Blog
Posts, notes, and articles.
- 0 - /blog/database-internals-storage-engines-transactions-and-recovery/ (section=blog)
- 1 - /blog/cpu-microarchitecture-pipelines-out-of-order-execution-and-modern-performance/ (section=blog)
- 2 - /blog/tls-pki-and-secure-protocols-how-encrypted-web-traffic-works/ (section=blog)
- 3 - /blog/inside-vector-databases-building-retrieval-augmented-systems-that-scale/ (section=blog)
- 4 - /blog/distributed-systems-consensus-consistency-and-fault-tolerance/ (section=blog)
- 5 - /blog/learned-indexes-when-models-replace-btrees/ (section=blog)
- 6 - /blog/the-100microsecond-rule-why-tail-latency-eats-your-throughput-and-how-to-fight-back/ (section=blog)
- 7 - /blog/the-quiet-calculus-of-probabilistic-commutativity/ (section=blog)
- 8 - /blog/the-hidden-backbone-of-parallelism-how-prefix-sums-power-distributed-computation/ (section=blog)
- 9 - /blog/gpudirect-storage-in-2025-optimizing-the-end-to-end-data-path/ (section=blog)
- 10 - /blog/mpi-vs.-openmp-in-2025-where-each-wins/ (section=blog)
- 11 - /blog/from-mapreduce-to-spark-the-arc-of-data-parallel-systems/ (section=blog)
- 12 - /blog/auditing-the-algorithm-building-a-responsible-ai-pipeline-that-scales/ (section=blog)
- 13 - /blog/memory-allocation-and-garbage-collection-how-programs-manage-memory/ (section=blog)
- 14 - /blog/scheduling-trading-latency-for-throughput-and-back-again/ (section=blog)
- 15 - /blog/exactly-once-in-streaming-what-it-means-and-how-systems-achieve-it/ (section=blog)
- 16 - /blog/tuning-cuda-with-the-gpu-memory-hierarchy/ (section=blog)
- 17 - /blog/write-ahead-logging-the-unsung-hero-of-database-durability/ (section=blog)
- 18 - /blog/bloom-filters-and-probabilistic-data-structures-trading-certainty-for-speed/ (section=blog)
- 19 - /blog/seeing-in-the-dark-observability-for-edge-ai-fleets/ (section=blog)
- 20 - /blog/adaptive-feature-flag-frameworks-for-hyper-growth-saas/ (section=blog)
- 21 - /blog/lock-free-data-structures-concurrency-without-the-wait/ (section=blog)
- 22 - /blog/amdahls-law-vs.-gustafsons-law-what-they-really-predict/ (section=blog)
- 23 - /blog/concurrency-primitives-and-synchronization-from-spinlocks-to-lock-free-data-structures/ (section=blog)
- 24 - /blog/unicode-and-character-encoding-from-ascii-to-utf-8-and-beyond/ (section=blog)
- 25 - /blog/countdown-to-quantum-migrating-an-enterprise-to-post-quantum-cryptography/ (section=blog)
- 26 - /blog/sealing-the-supply-chain-zero-trust-build-pipelines-that-scale/ (section=blog)
- 27 - /blog/file-systems-and-storage-internals-how-data-persists-on-disk/ (section=blog)
- 28 - /blog/memory-allocators-from-malloc-to-modern-arena-allocators/ (section=blog)
- 29 - /blog/reverse-indexing-and-inverted-files-how-search-engines-fly/ (section=blog)
- 30 - /blog/latency-aware-edge-inference-platforms-engineering-consistent-ai-experiences/ (section=blog)
- 31 - /blog/keeping-the-model-awake-building-a-self-healing-ml-inference-platform/ (section=blog)
- 32 - /blog/tcp-congestion-control-from-slow-start-to-bbr/ (section=blog)
- 33 - /blog/floating-point-how-computers-represent-real-numbers/ (section=blog)
- 34 - /blog/garbage-collection-algorithms-from-mark-and-sweep-to-zgc/ (section=blog)
- 35 - /blog/timeouts-retries-and-idempotency-keys-a-practical-guide/ (section=blog)
- 36 - /blog/teaching-graphql-to-cache-at-the-edge/ (section=blog)
- 37 - /blog/designing-crdt-powered-collaboration-platforms-that-stay-consistent/ (section=blog)
- 38 - /blog/cpu-caches-and-cache-coherence-the-memory-hierarchy-that-makes-modern-computing-fast/ (section=blog)
- 39 - /blog/virtual-memory-and-page-tables-how-modern-systems-manage-memory/ (section=blog)
- 40 - /blog/process-scheduling-and-context-switching-how-operating-systems-share-the-cpu/ (section=blog)
- 41 - /blog/software-supply-chain-security-sboms-sigstore-reproducible-builds-and-attestation/ (section=blog)
- 42 - /blog/branch-prediction-and-speculative-execution-how-modern-cpus-gamble-on-the-future/ (section=blog)
- 43 - /blog/virtual-memory-and-page-tables-how-operating-systems-manage-memory/ (section=blog)
- 44 - /blog/b-trees-and-lsm-trees-the-foundations-of-modern-storage-engines/ (section=blog)
- 45 - /blog/cpu-caches-and-memory-hierarchy-the-hidden-architecture-behind-performance/ (section=blog)
- 46 - /blog/instrumenting-without-spying-privacy-preserving-telemetry-at-scale/ (section=blog)
- 47 - /blog/deterministic-monorepo-ci-platforms-engineering-consistency-at-scale/ (section=blog)
- 48 - /blog/system-calls-the-gateway-between-user-space-and-kernel/ (section=blog)
- 49 - /blog/cachefriendly-data-layouts-aos-vs.-soa-and-the-hybrid-inbetween/ (section=blog)
- 50 - /blog/raft-fastcommit-and-prevote-in-practice/ (section=blog)
- 51 - /blog/network-sockets-and-the-tcp/ip-stack-how-data-travels-across-networks/ (section=blog)
- 52 - /blog/safe-rollback-strategies-for-distributed-databases/ (section=blog)
- 53 - /blog/compiler-optimizations-from-source-code-to-fast-machine-code/ (section=blog)
- 54 - /blog/merkle-trees-and-contentaddressable-storage/ (section=blog)
- 55 - /blog/consistent-hashing-distributing-data-across-dynamic-clusters/ (section=blog)
- 56 - /blog/tuning-the-dial-adaptive-consistency-at-planet-scale/ (section=blog)
- 57 - /blog/when-data-centers-learned-to-sleep-energy-aware-scheduling-in-practice/ (section=blog)
- 58 - /blog/speculative-prefetchers-designing-memory-systems-that-read-the-future/ (section=blog)
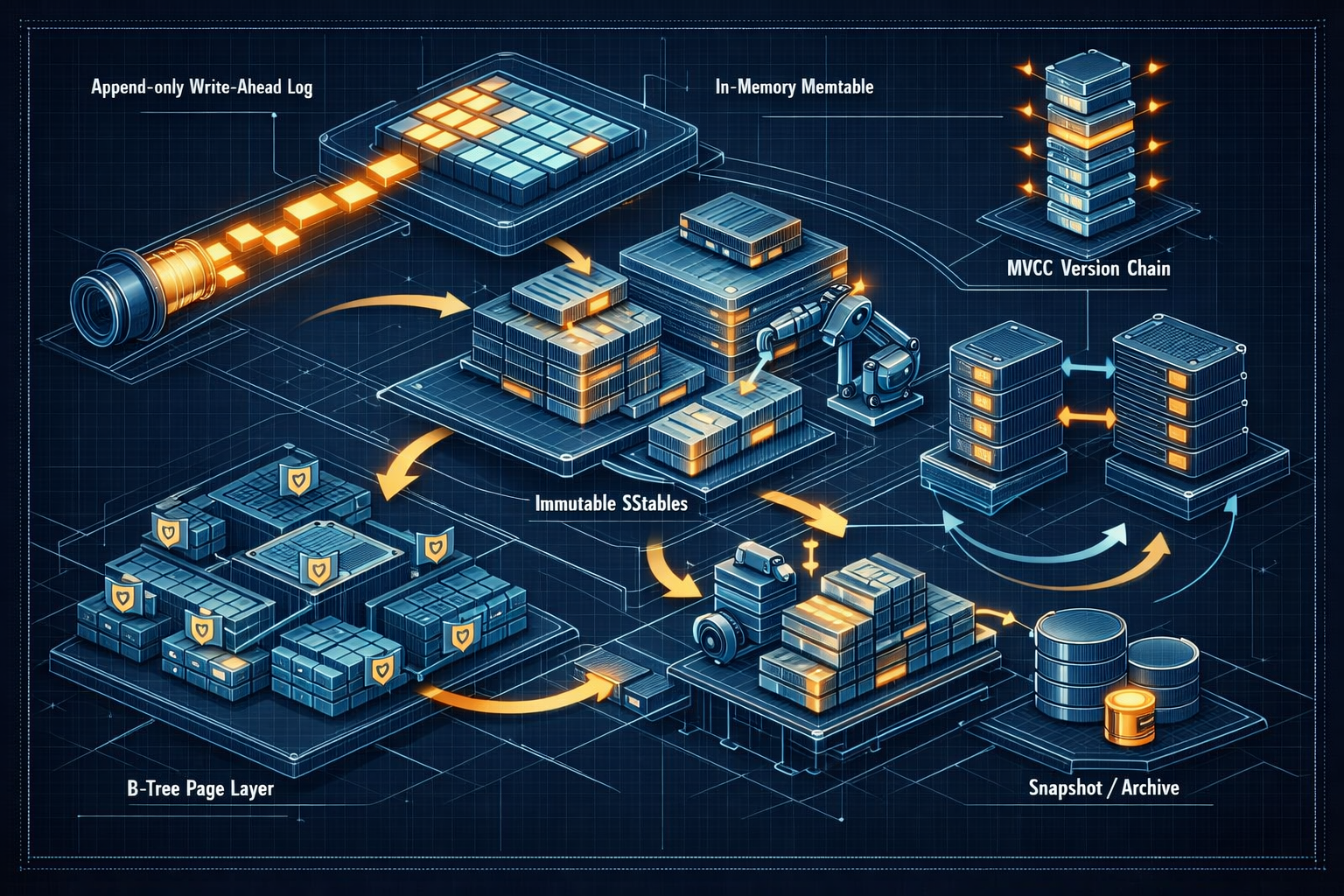
Database Internals: Storage Engines, Transactions, and Recovery
2025-12-21A deep technical walkthrough of how databases store data, ensure correctness, and recover from crashes — covering B-trees, LSM-trees, write-ahead logging, MVCC, isolation levels, and replication.
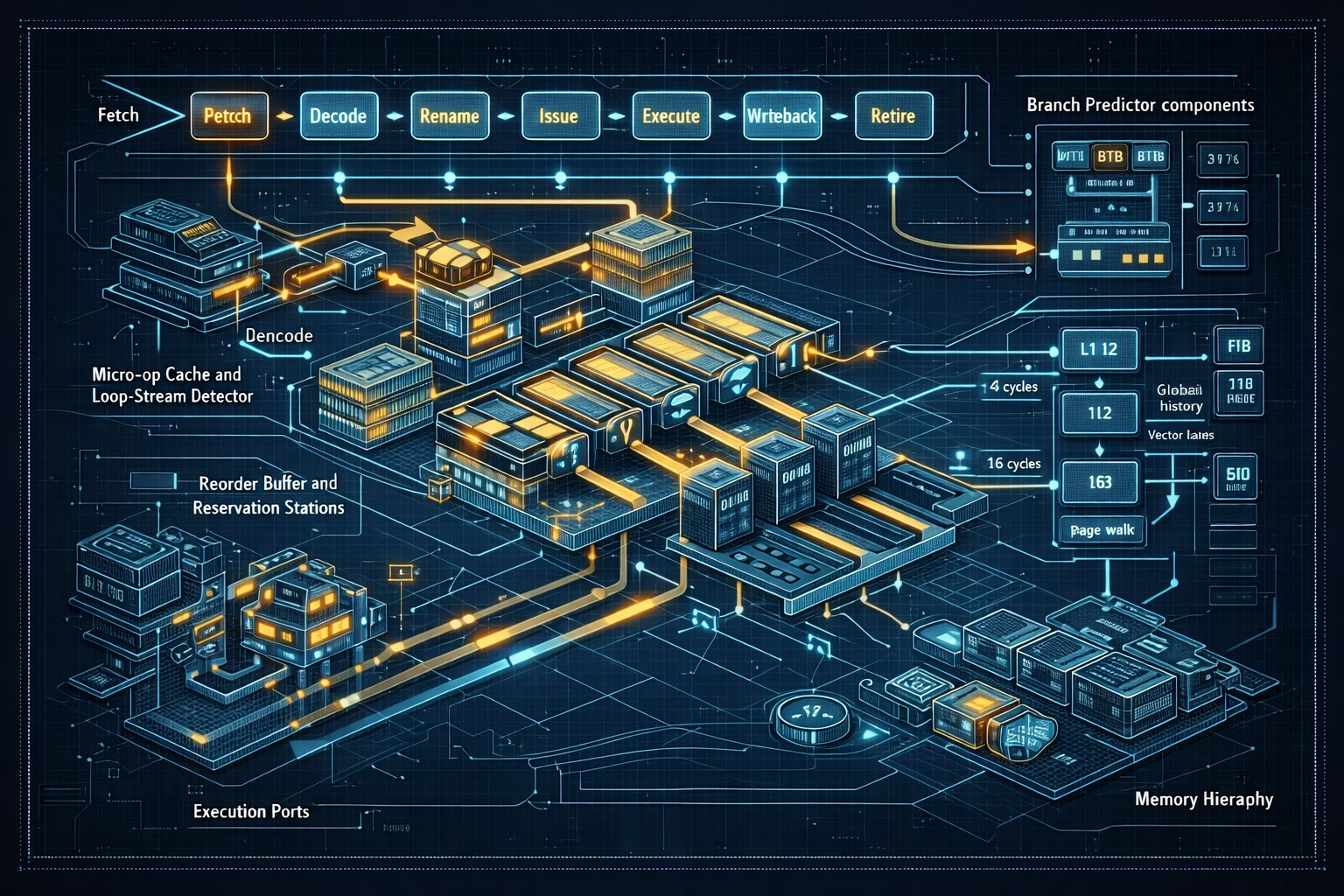
CPU Microarchitecture: Pipelines, Out-of-Order Execution, and Modern Performance
2025-12-04An in-depth exploration of CPU microarchitecture: instruction pipelines, hazards, branch prediction, out-of-order execution, register renaming, superscalar and SIMD units, and how software maps to hardware for performance.
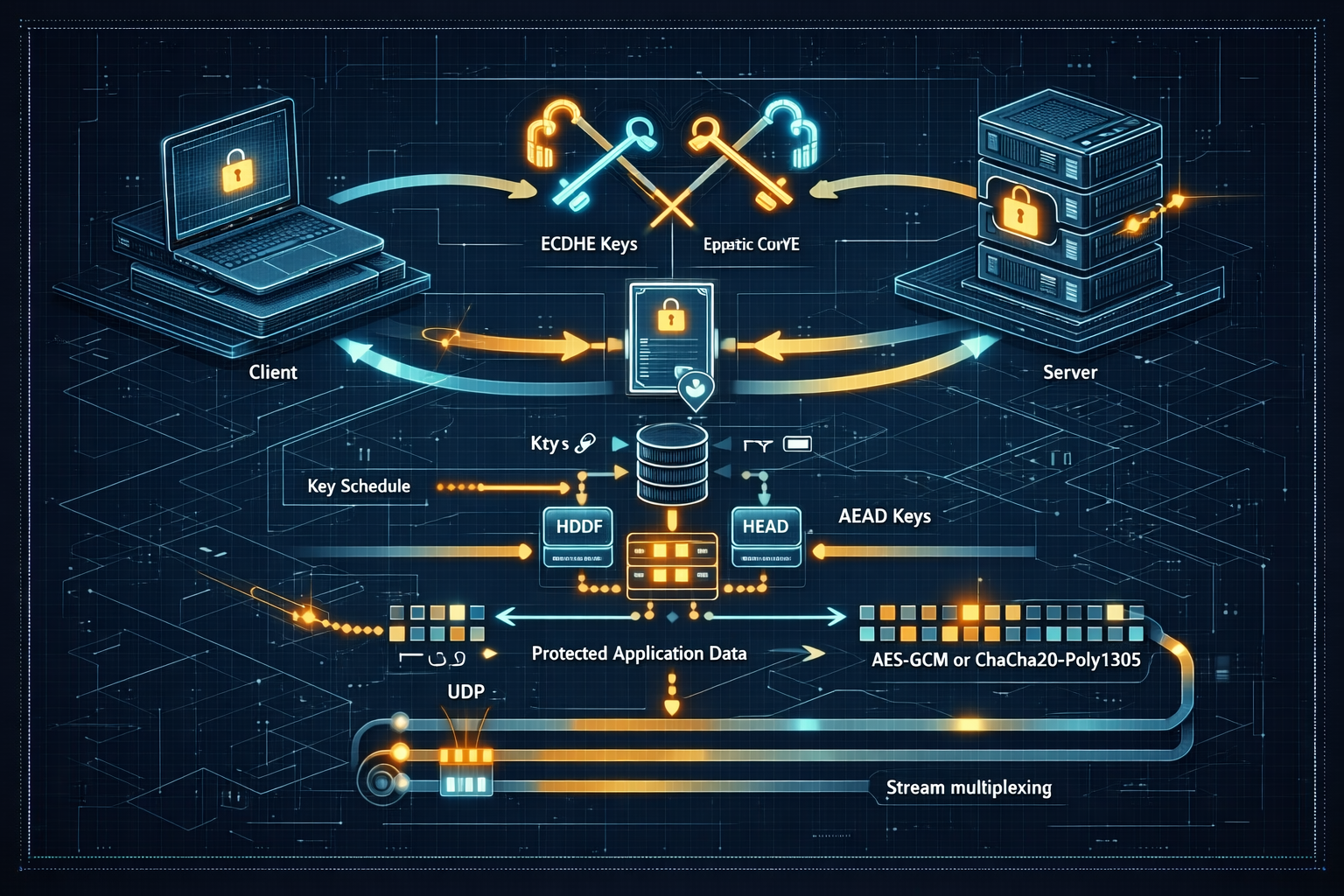
TLS, PKI, and Secure Protocols: How Encrypted Web Traffic Works
2025-11-18A deep technical guide to TLS, certificate validation, key exchange, record protection, modern cipher suites, TLS 1.3, QUIC, and practical deployment best practices for secure networked applications.

Inside Vector Databases: Building Retrieval-Augmented Systems that Scale
2025-10-26How modern vector databases ingest, index, and serve embeddings for production retrieval-augmented generation systems without falling over.
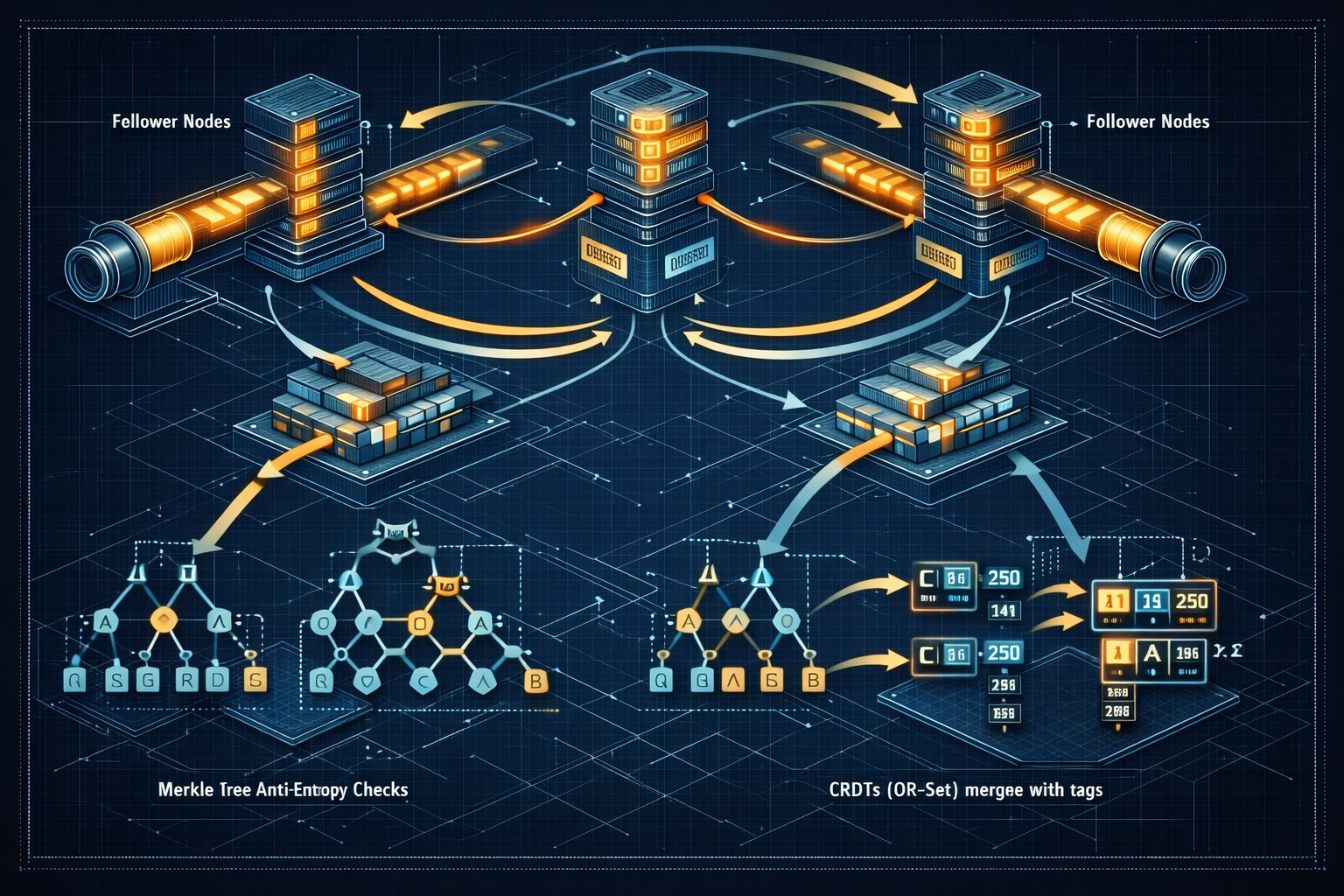
Distributed Systems: Consensus, Consistency, and Fault Tolerance
2025-10-20Fundamentals of distributed systems: failure models, consensus algorithms (Paxos, Raft), CAP theorem, consistency models, gossip, membership, CRDTs, and practical testing strategies like Jepsen.
Learned Indexes: When Models Replace B‑Trees
2025-10-04A practitioner's guide to learned indexes: how they work, when they beat classic data structures, and what it takes to ship them without getting paged.

The 100‑Microsecond Rule: Why Tail Latency Eats Your Throughput (and How to Fight Back)
2025-10-04A field guide to taming P99 in modern systems—from queueing math to NIC interrupts, from hedged requests to adaptive concurrency. Practical patterns, pitfalls, and a blueprint you can apply this week.
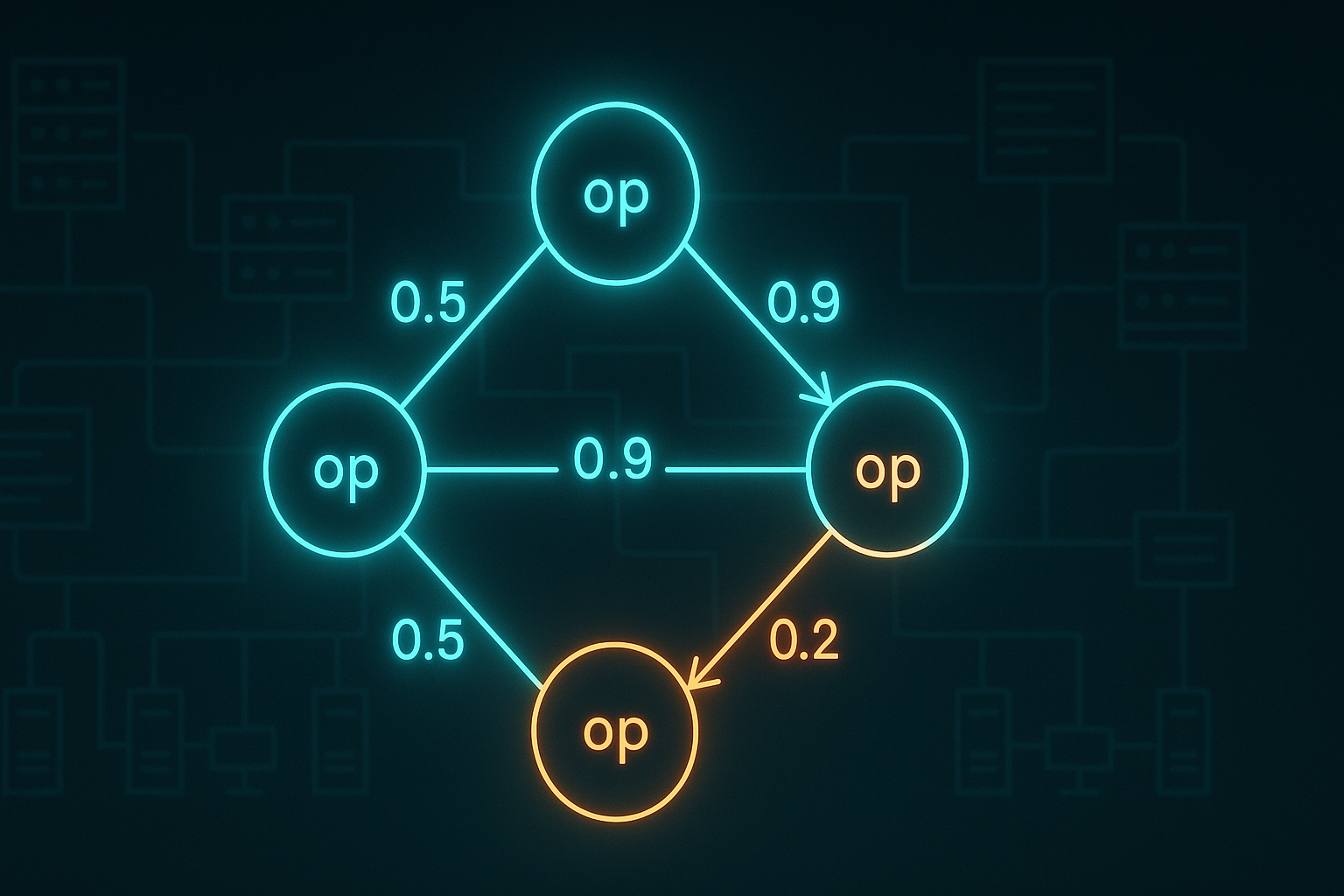
The Quiet Calculus of Probabilistic Commutativity
2025-09-27A practical calculus for quantifying when non-commutative operations in distributed systems can be safely executed without heavyweight coordination.

The Hidden Backbone of Parallelism: How Prefix Sums Power Distributed Computation
2025-09-21Discover how the humble prefix sum (scan) quietly powers GPUs, distributed clusters, and big data frameworks—an obscure but essential building block of parallel and distributed computation.

GPUDirect Storage in 2025: Optimizing the End-to-End Data Path
2025-09-16How modern systems move data from NVMe and object storage into GPU kernels with minimal CPU overhead and maximal throughput.
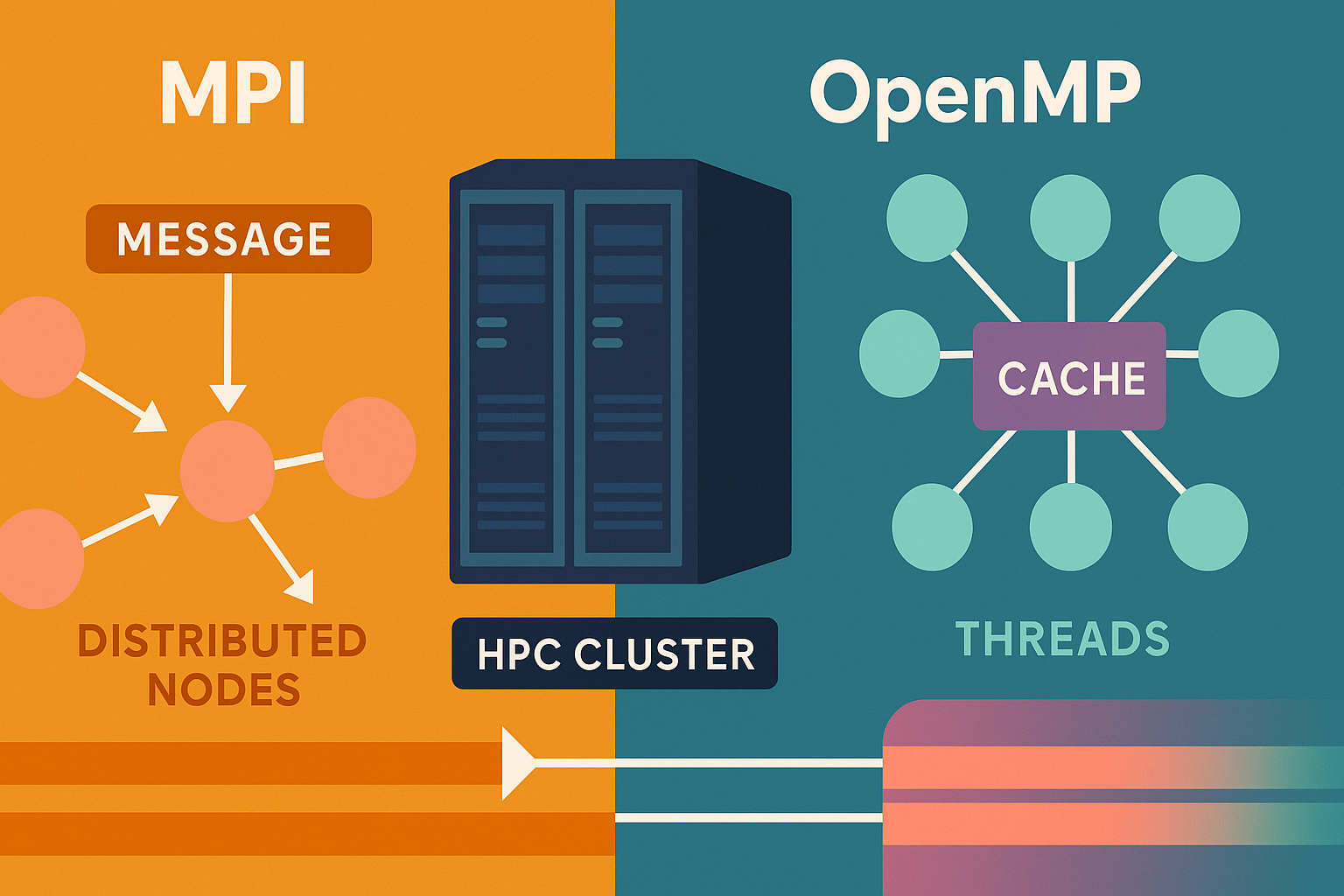
MPI vs. OpenMP in 2025: Where Each Wins
2025-07-04A practical guide to choosing between message passing and shared-memory parallelism for modern HPC and hybrid nodes.

From MapReduce to Spark: The Arc of Data-Parallel Systems
2025-05-19MapReduce taught fault-tolerant batch at scale; Spark generalized it with resilient distributed datasets (RDDs) and DAG scheduling.

Auditing the Algorithm: Building a Responsible AI Pipeline That Scales
2025-04-05How we operationalized responsible AI with automated audits, governance rituals, and transparent reporting.
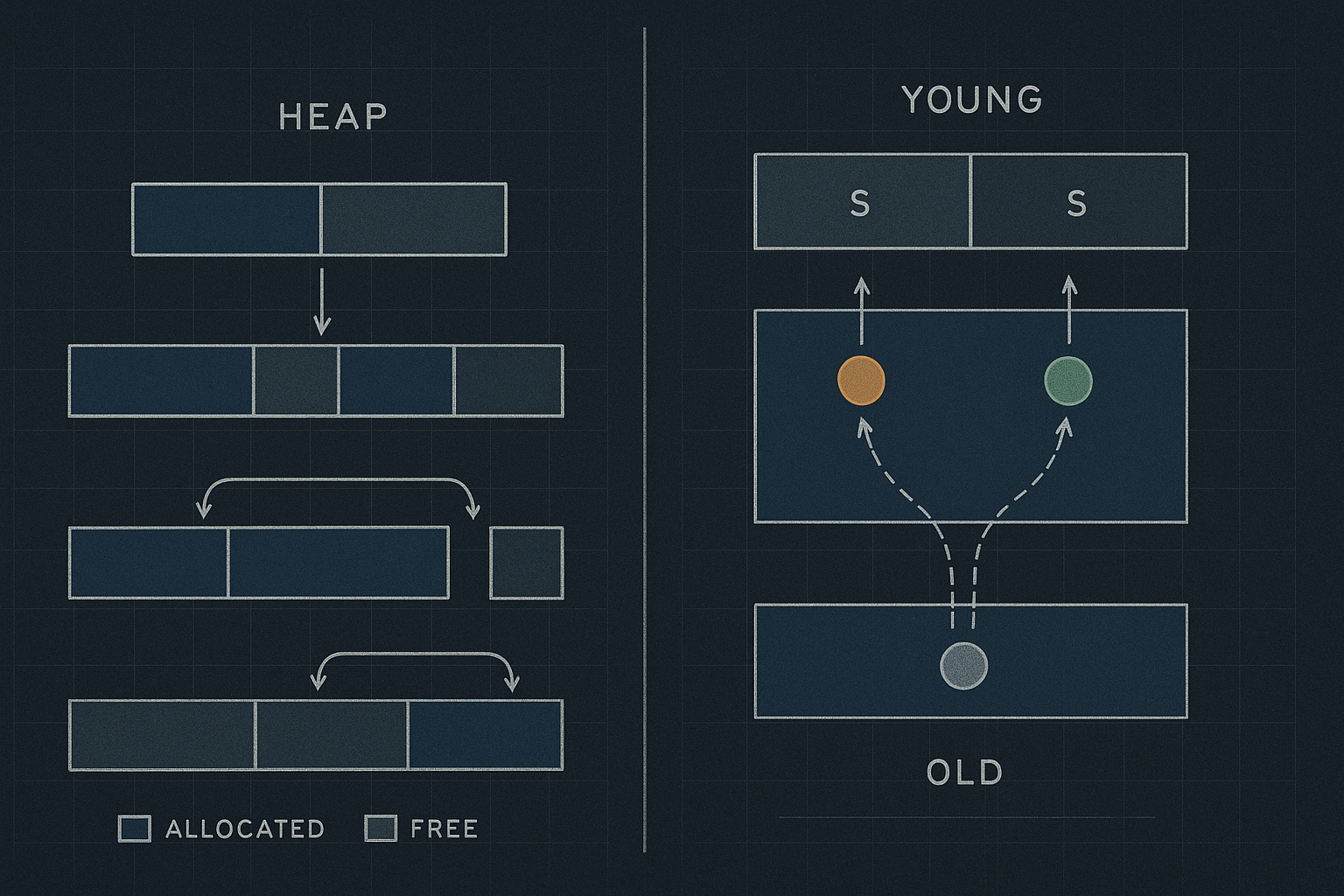
Memory Allocation and Garbage Collection: How Programs Manage Memory
2025-02-20A deep dive into how programming languages allocate, track, and reclaim memory. Understand malloc internals, garbage collection algorithms, and the trade-offs that shape runtime performance.
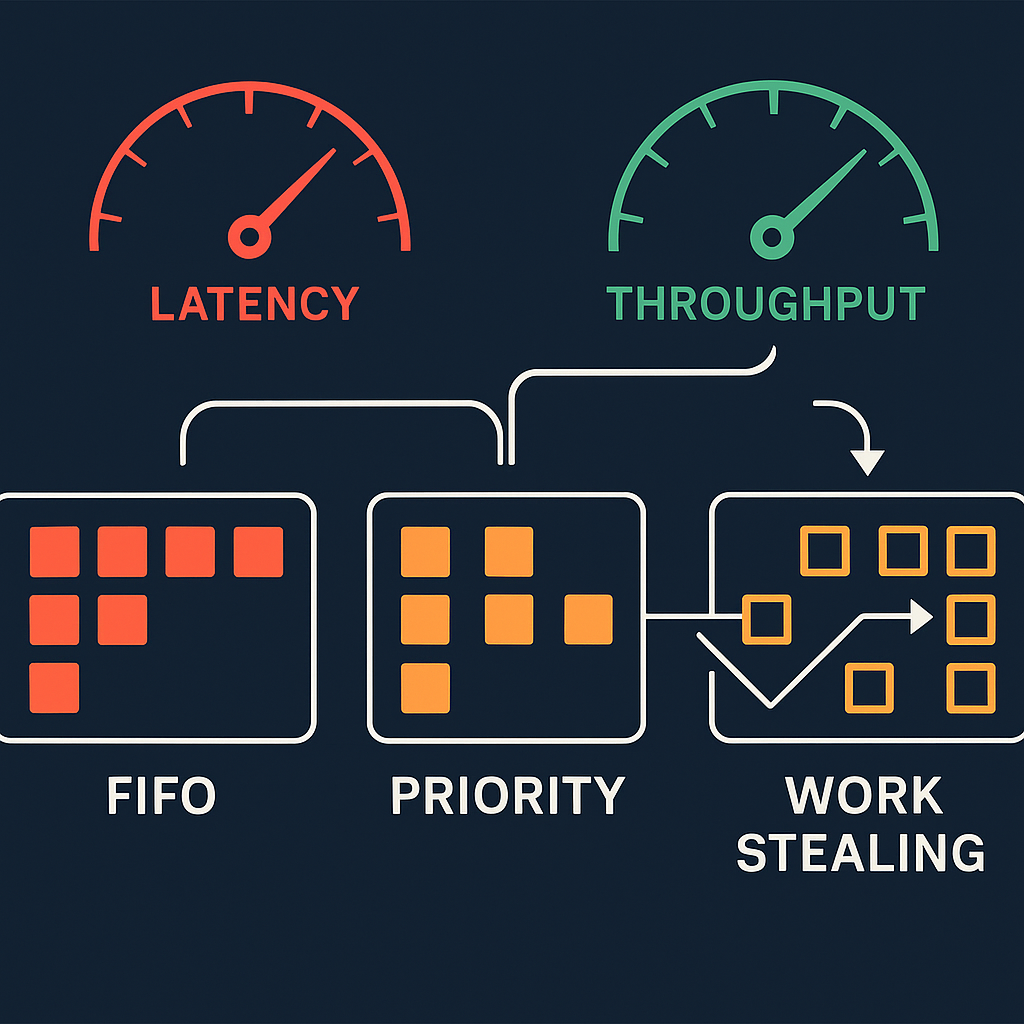
Scheduling: Trading Latency for Throughput (and Back Again)
2025-02-12Queue disciplines, work stealing, and CPU affinity: how scheduler choices shape p50/p99, and when to bias for one over the other.

Exactly-Once in Streaming: What It Means and How Systems Achieve It
2025-01-22Disentangle marketing from mechanisms: idempotence, transactions, and state snapshots behind ‘exactly-once’.
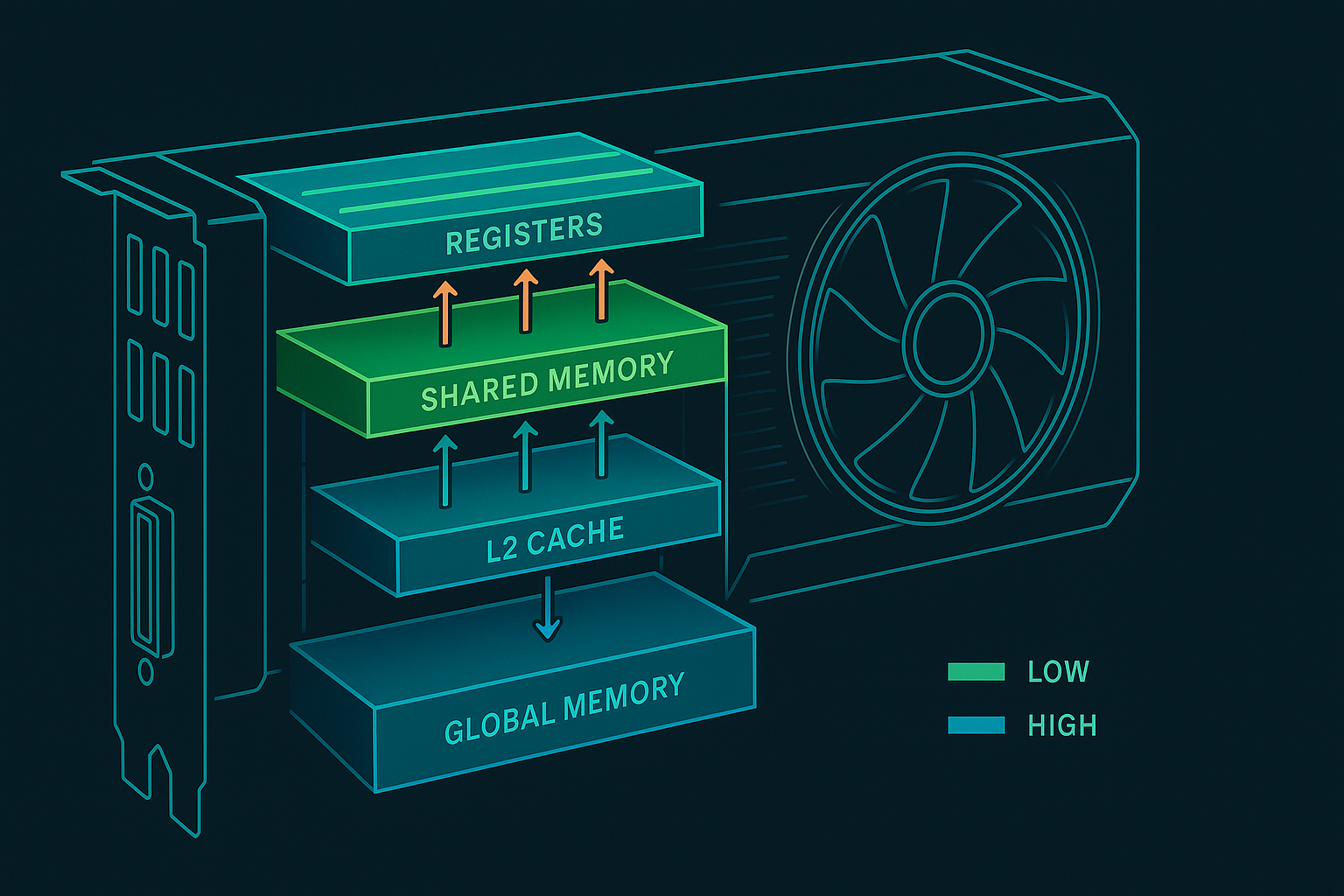
Tuning CUDA with the GPU Memory Hierarchy
2024-11-27Global, shared, and register memory each have distinct latency and bandwidth. Performance comes from the right access pattern.

Write-Ahead Logging: The Unsung Hero of Database Durability
2024-09-10Dive deep into write-ahead logging (WAL), the technique that lets databases promise durability without sacrificing performance. Learn how WAL works, why it matters, and how modern systems push its limits.

Bloom Filters and Probabilistic Data Structures: Trading Certainty for Speed
2024-08-22Explore how Bloom filters, Count-Min sketches, and HyperLogLog sacrifice perfect accuracy for dramatic space and time savings—and learn when that trade-off makes sense.
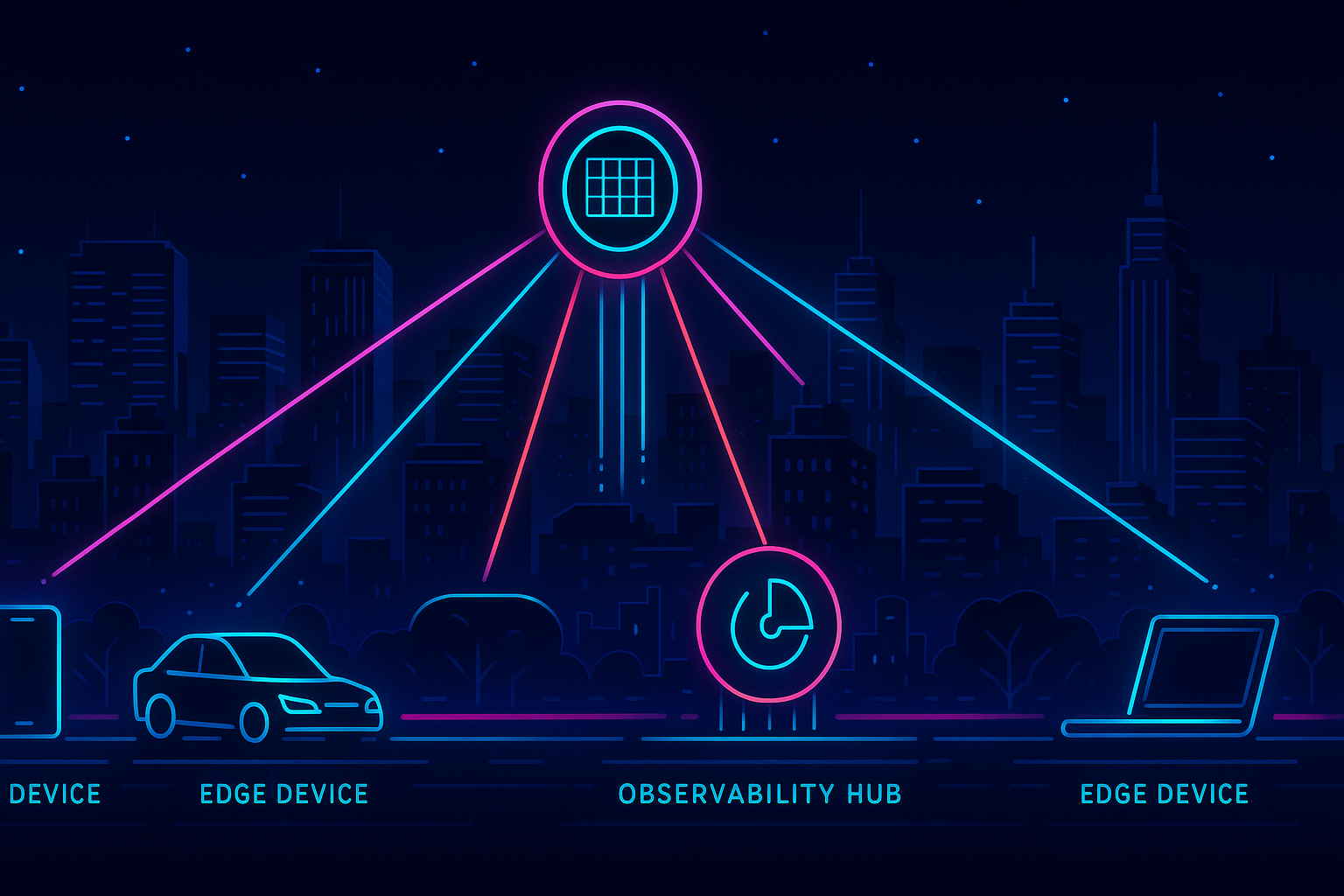
Seeing in the Dark: Observability for Edge AI Fleets
2024-08-16A practitioner's guide to instrumenting, monitoring, and debugging machine learning models running at the edge.
Adaptive Feature Flag Frameworks for Hyper-Growth SaaS
2024-08-15A comprehensive field guide to building resilient, data-db7735b feature flag platforms that keep hyper-growth SaaS releases safe, fast, and customer-centric.
Lock-Free Data Structures: Concurrency Without the Wait
2024-07-18Explore how lock-free algorithms achieve thread-safe data access without traditional locks. Learn the theory behind compare-and-swap, the ABA problem, memory ordering, and practical implementations that power high-performance systems.

Amdahl’s Law vs. Gustafson’s Law: What They Really Predict
2024-06-15When does parallelism pay off? Compare Amdahl’s and Gustafson’s models, see where each applies, and learn how to reason about speedups in practice.

Concurrency Primitives and Synchronization: From Spinlocks to Lock-Free Data Structures
2024-03-15A comprehensive exploration of concurrent programming fundamentals, covering mutexes, spinlocks, semaphores, condition variables, memory ordering, and lock-free programming techniques that enable safe parallel execution.