Consistent Hashing: Distributing Data Across Dynamic Clusters
A deep dive into consistent hashing, the elegant algorithm that enables scalable distributed systems. Learn how it works, why it matters for databases and caches, and explore modern variations like jump consistent hashing and rendezvous hashing.
When you add a server to your distributed cache, what happens to all the cached data? With naive hashing, almost everything moves—a catastrophic reshuffling that defeats the purpose of caching. Consistent hashing solves this elegantly: only K/N keys need to move, where K is total keys and N is the number of servers. This simple idea underpins some of the most scalable systems ever built. Let’s explore how it works and why it matters.
1. The Problem with Simple Hashing
Consider a distributed cache with N servers. The naive approach:
def get_server(key, num_servers):
return hash(key) % num_servers
This works beautifully—until you add or remove a server.
1.1 The Reshuffling Disaster
With 4 servers, keys hash to servers 0-3:
key hash(key) hash % 4 hash % 5 (after adding server)
────────────────────────────────────────────────────────────
"a" 12345 1 0 ← moved!
"b" 67890 2 0 ← moved!
"c" 11111 3 1 ← moved!
"d" 22222 2 2 ← stayed
"e" 33333 1 3 ← moved!
Adding one server moved 4 out of 5 keys! In general, adding a server moves approximately (N-1)/N of all keys—80% with 5 servers, 99% with 100 servers.
For a cache, this means:
- Almost all cache entries become invalid
- The database gets hammered with requests
- Performance crashes exactly when you’re trying to scale up
1.2 The Goal
We want a hashing scheme where:
- Adding a server moves only
~K/Nkeys (those that should go to the new server) - Removing a server moves only
~K/Nkeys (those from the removed server) - Load is distributed evenly across servers
Consistent hashing achieves all three.
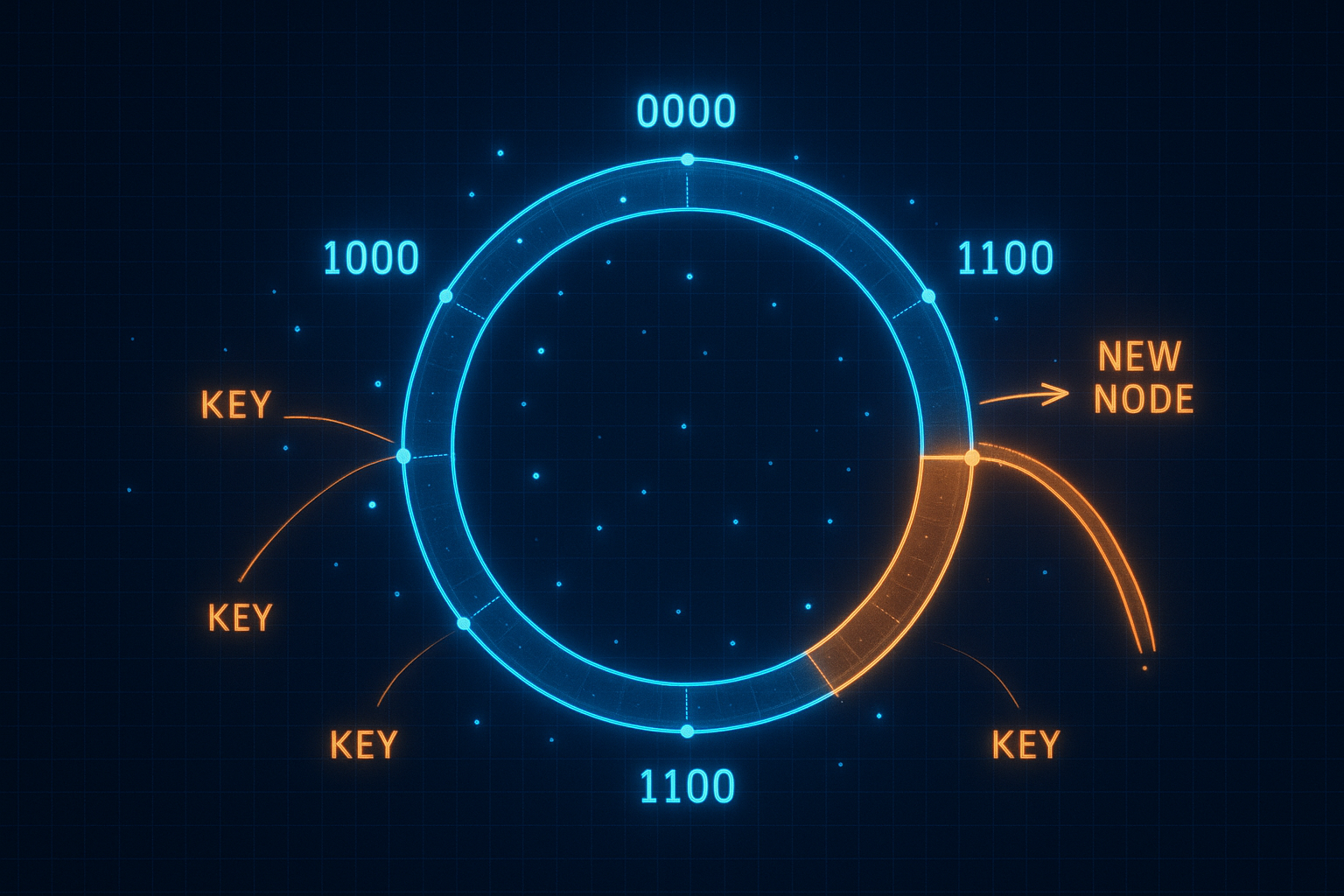
2. The Consistent Hashing Ring
The key insight: hash both keys and servers onto the same circular space.
2.1 The Ring Structure
Imagine a circle (ring) with positions 0 to 2³²-1 (using a 32-bit hash):
0
│
┌────┴────┐
│ │
┌────┘ └────┐
│ │
2^32-1 2^31
│ │
└────┐ ┌────┘
│ │
└────┬────┘
│
2^32-1/2
Both servers and keys are hashed to positions on this ring:
def hash_to_ring(item):
return hash(item) % (2**32)
# Servers
server_a_pos = hash_to_ring("server-a.example.com") # e.g., 1000000
server_b_pos = hash_to_ring("server-b.example.com") # e.g., 2500000
server_c_pos = hash_to_ring("server-c.example.com") # e.g., 3800000
2.2 Key Assignment
A key is assigned to the first server encountered when walking clockwise from the key’s position:
Ring positions (simplified 0-100 scale):
0
│
├── Server A (10)
│
├── Key "foo" (25) ──────► Goes to Server B
│
├── Server B (30)
│
├── Key "bar" (55) ──────► Goes to Server C
│
├── Server C (60)
│
├── Key "baz" (85) ──────► Goes to Server A (wraps around)
│
100/0
def get_server(key, sorted_servers):
"""Find the first server clockwise from the key's position."""
key_pos = hash_to_ring(key)
for server_pos, server_name in sorted_servers:
if server_pos >= key_pos:
return server_name
# Wrap around to first server
return sorted_servers[0][1]
2.3 Adding a Server
When server D joins at position 45:
Before:
Keys 31-60 → Server C
After:
Keys 31-45 → Server D (new)
Keys 46-60 → Server C (unchanged)
Only keys in the range [31, 45] move—approximately 1/N of the keyspace. All other keys remain on their current servers.
2.4 Removing a Server
When server B leaves:
Before:
Keys 11-30 → Server B
After:
Keys 11-30 → Server C (next clockwise)
Again, only ~1/N of keys move—those that were on the removed server.
3. Virtual Nodes
The basic ring has a problem: servers may not be evenly distributed, causing load imbalance.
3.1 The Imbalance Problem
With 3 servers randomly placed:
0
│
├── Server A (5)
│
│ ← A handles 5% of ring
│
├── Server B (10)
│
│
│
│ ← B handles 60% of ring!
│
│
│
├── Server C (70)
│
│ ← C handles 35% of ring
│
100
Server B handles 60% of traffic while A handles only 5%. This defeats the purpose of distribution!
3.2 Virtual Nodes Solution
Instead of one position per server, use many virtual positions:
def add_server(ring, server_name, num_virtual_nodes=150):
for i in range(num_virtual_nodes):
virtual_id = f"{server_name}#vnode{i}"
position = hash_to_ring(virtual_id)
ring[position] = server_name
With 150 virtual nodes per server, each server gets ~150 positions scattered around the ring:
0
├── A#vnode42 (2)
├── C#vnode17 (5)
├── B#vnode89 (8)
├── A#vnode3 (12)
├── B#vnode45 (15)
├── C#vnode91 (18)
│ ...
100
Now each server handles approximately 1/N of the ring, regardless of the random hash positions.
3.3 Load Distribution Analysis
With V virtual nodes per server:
- Standard deviation of load:
~1/√(V*N) - With 150 virtual nodes and 10 servers:
~2.6%standard deviation - With 1000 virtual nodes and 10 servers:
~1%standard deviation
The trade-off: more virtual nodes means better balance but more memory and lookup time.
3.4 Heterogeneous Servers
Virtual nodes enable weighted distribution:
# Server with 2x capacity gets 2x virtual nodes
add_server(ring, "big-server", num_virtual_nodes=300)
add_server(ring, "small-server", num_virtual_nodes=150)
This naturally distributes load proportional to server capacity.
4. Implementation Details
4.1 Efficient Lookup
A naive linear search is O(N×V). Use a sorted data structure:
import bisect
class ConsistentHash:
def __init__(self, num_virtual_nodes=150):
self.num_virtual_nodes = num_virtual_nodes
self.ring = [] # Sorted list of (position, server)
self.servers = {} # server -> list of positions
def add_server(self, server):
positions = []
for i in range(self.num_virtual_nodes):
pos = hash_to_ring(f"{server}#vnode{i}")
positions.append(pos)
# Insert into sorted ring
bisect.insort(self.ring, (pos, server))
self.servers[server] = positions
def remove_server(self, server):
for pos in self.servers[server]:
# Remove from ring (O(n) but infrequent)
self.ring.remove((pos, server))
del self.servers[server]
def get_server(self, key):
if not self.ring:
return None
pos = hash_to_ring(key)
# Binary search for first position >= key
idx = bisect.bisect_left(self.ring, (pos,))
if idx == len(self.ring):
idx = 0 # Wrap around
return self.ring[idx][1]
Lookup is O(log(N×V)), typically <10 comparisons even with millions of virtual nodes.
4.2 Hash Function Choice
The hash function must:
- Distribute uniformly (avoid clustering)
- Be deterministic (same input → same output)
- Be fast (called frequently)
Good choices:
import hashlib
def hash_to_ring_md5(item):
"""MD5 - good distribution, cryptographic (slower)."""
return int(hashlib.md5(item.encode()).hexdigest(), 16) % (2**32)
def hash_to_ring_xxhash(item):
"""xxHash - excellent distribution, very fast."""
import xxhash
return xxhash.xxh32(item.encode()).intdigest()
def hash_to_ring_murmur(item):
"""MurmurHash3 - good distribution, fast."""
import mmh3
return mmh3.hash(item, signed=False)
Avoid:
- Python’s built-in
hash()(not consistent across runs) - CRC32 (poor distribution for some inputs)
- Simple polynomial hashes (clustering prone)
4.3 Handling Replication
For fault tolerance, replicate data across multiple servers:
def get_servers(self, key, num_replicas=3):
"""Get N servers for a key, walking clockwise."""
if not self.ring:
return []
pos = hash_to_ring(key)
idx = bisect.bisect_left(self.ring, (pos,))
servers = []
seen = set()
while len(servers) < num_replicas and len(seen) < len(self.servers):
if idx >= len(self.ring):
idx = 0
server = self.ring[idx][1]
if server not in seen:
servers.append(server)
seen.add(server)
idx += 1
return servers
This ensures replicas are on different physical servers, not just different virtual nodes of the same server.
5. Real-World Applications
5.1 Amazon DynamoDB (Dynamo Paper)
Dynamo pioneered consistent hashing for databases:
- Each node responsible for a range of the ring
- Replication across N consecutive nodes
- Vector clocks for conflict resolution
- Sloppy quorum for availability
Ring with replication factor 3:
Key K hashes to position P
├── Primary: First node clockwise from P
├── Replica 1: Second node clockwise
└── Replica 2: Third node clockwise
5.2 Apache Cassandra
Cassandra uses consistent hashing with virtual nodes:
# cassandra.yaml
num_tokens: 256 # Virtual nodes per server
With 256 tokens per node and 10 nodes:
- 2560 total positions on the ring
- Load variance < 5%
- Adding a node moves only ~10% of data
5.3 Memcached Clients
Memcached servers are independent; consistent hashing is implemented client-side:
# libmemcached configuration
memcached_servers = [
"cache1.example.com:11211",
"cache2.example.com:11211",
"cache3.example.com:11211",
]
# Client uses consistent hashing to pick server
client = pylibmc.Client(memcached_servers, behaviors={
"ketama": True, # Consistent hashing algorithm
"ketama_weighted": True, # Support weighted servers
})
This allows cache servers to be added/removed without invalidating the entire cache.
5.4 Load Balancers
Nginx uses consistent hashing for upstream selection:
upstream backend {
hash $request_uri consistent;
server backend1.example.com weight=5;
server backend2.example.com weight=3;
server backend3.example.com weight=2;
}
This ensures the same URL always goes to the same backend, enabling per-server caching.
5.5 Content Delivery Networks
CDNs use consistent hashing to route requests to edge servers:
- Hash the content URL
- Route to the nearest edge server handling that hash range
- If the edge server fails, traffic moves to the next server on the ring
This minimizes cache invalidation when edge servers fail or are added.
6. Alternatives and Variations
6.1 Rendezvous Hashing (HRW)
Rendezvous hashing (Highest Random Weight) takes a different approach:
def get_server_hrw(key, servers):
"""Each server gets a score; highest score wins."""
def score(server):
# Combine key and server into a single hash
combined = f"{key}:{server}"
return hash_to_ring(combined)
return max(servers, key=score)
Advantages:
- No ring structure needed
- O(N) lookup, but simple and cache-friendly
- Perfect load balance (no virtual nodes needed)
- Adding a server moves exactly 1/N keys
Disadvantages:
- O(N) per lookup (vs. O(log N) for ring)
- Less flexible than virtual nodes for weighting
6.2 Jump Consistent Hashing
Google’s jump consistent hash is remarkably simple:
def jump_consistent_hash(key, num_buckets):
"""Google's jump consistent hash - O(log n), no memory."""
b, j = -1, 0
while j < num_buckets:
b = j
key = ((key * 2862933555777941757) + 1) & 0xFFFFFFFFFFFFFFFF
j = int((b + 1) * (1 << 31) / ((key >> 33) + 1))
return b
Amazing properties:
- O(log N) time complexity
- Zero memory (no ring to store!)
- Perfect load balance
- Minimal movement (exactly K/N keys move)
Limitations:
- Only supports sequential bucket IDs (0 to N-1)
- Can’t remove arbitrary servers (only remove from the end)
- No support for heterogeneous servers
Perfect for: Sharded databases where servers are numbered 0 to N-1.
6.3 Maglev Hashing
Google’s Maglev load balancer uses a lookup table approach:
def build_maglev_table(servers, table_size=65537):
"""Build a lookup table for O(1) server selection."""
# Each server gets a permutation of table positions
permutations = {}
for server in servers:
# Generate a permutation unique to this server
seed1 = hash_to_ring(f"{server}:offset")
seed2 = hash_to_ring(f"{server}:skip")
offset = seed1 % table_size
skip = seed2 % (table_size - 1) + 1
permutations[server] = [
(offset + i * skip) % table_size
for i in range(table_size)
]
# Build table: each position assigned to first server that "wants" it
table = [None] * table_size
next_index = {s: 0 for s in servers}
filled = 0
while filled < table_size:
for server in servers:
while True:
pos = permutations[server][next_index[server]]
next_index[server] += 1
if table[pos] is None:
table[pos] = server
filled += 1
break
return table
Properties:
- O(1) lookup (just
table[hash(key) % table_size]) - Good load balance
- Minimal disruption (similar to consistent hashing)
- Deterministic (same table on all clients)
Used in: Google’s network load balancers, some CDNs.
6.4 Multi-Probe Consistent Hashing
Microsoft’s approach: probe multiple positions, pick the least-loaded:
def get_server_multiprobe(key, ring, num_probes=21):
"""Probe multiple positions, return least-loaded server."""
candidates = []
for i in range(num_probes):
probe_key = f"{key}:probe{i}"
pos = hash_to_ring(probe_key)
server = ring.get_server_at(pos)
candidates.append(server)
# Return least-loaded among candidates
return min(candidates, key=lambda s: s.current_load)
This combines consistent hashing with load awareness for better balance.
7. Handling Failures and Recovery
7.1 Detecting Failures
Consistent hashing doesn’t detect failures; it needs a failure detection layer:
- Heartbeats: Servers periodically ping each other
- Gossip protocol: Failure information spreads exponentially
- Health checks: Load balancers probe backends
class ConsistentHashWithHealth:
def __init__(self):
self.ring = ConsistentHash()
self.healthy_servers = set()
def get_server(self, key):
# Walk the ring until we find a healthy server
servers = self.ring.get_servers(key, num_replicas=10)
for server in servers:
if server in self.healthy_servers:
return server
return None # All servers down!
7.2 Graceful Removal
When removing a server, move data before removal:
def remove_server_graceful(ring, server_to_remove):
# 1. Find all keys owned by this server
keys_to_move = get_keys_for_server(server_to_remove)
# 2. For each key, find the next server (after removal)
ring.remove_server(server_to_remove)
# 3. Copy data to new owners (before actual shutdown)
for key in keys_to_move:
new_server = ring.get_server(key)
copy_data(key, server_to_remove, new_server)
# 4. Now safe to shut down
shutdown(server_to_remove)
7.3 Handling Hotspots
Some keys are accessed much more than others. Solutions:
Client-side caching: Cache hot keys locally.
local_cache = {}
def get(key):
if key in local_cache:
return local_cache[key]
server = ring.get_server(key)
value = server.get(key)
if is_hot(key):
local_cache[key] = value
return value
Key splitting: Distribute hot keys across multiple servers.
def get_key_with_splitting(base_key, is_write=False):
if is_hot(base_key) and not is_write:
# Read from random replica
suffix = random.randint(0, 9)
return f"{base_key}:split{suffix}"
return base_key
Request coalescing: Batch multiple requests for the same key.
8. Consistent Hashing at Scale
8.1 Multi-Datacenter Deployment
With multiple datacenters, consistent hashing operates at two levels:
Level 1: Datacenter selection
hash(key) → Datacenter
Level 2: Server selection within datacenter
hash(key) → Server in selected datacenter
For latency, prefer the local datacenter but fall back to remote:
def get_server_multi_dc(key, local_dc, all_dcs):
# Try local datacenter first
local_servers = all_dcs[local_dc].get_servers(key, num_replicas=3)
healthy_local = [s for s in local_servers if s.healthy]
if healthy_local:
return healthy_local[0]
# Fall back to other datacenters
for dc in all_dcs:
if dc != local_dc:
servers = all_dcs[dc].get_servers(key, num_replicas=3)
healthy = [s for s in servers if s.healthy]
if healthy:
return healthy[0]
return None
8.2 Handling Network Partitions
During a partition, different clients may see different ring states:
Client A sees: [Server1, Server2, Server3]
Client B sees: [Server1, Server2] (Server3 appears down)
Key K: Client A routes to Server3
Client B routes to Server1
Result: Inconsistency!
Solutions:
Sloppy quorum: Write to any N available nodes, read from any N nodes:
def write_sloppy(key, value, ring, n=3, w=2):
servers = ring.get_healthy_servers(key, n)
successes = 0
for server in servers:
try:
server.put(key, value)
successes += 1
except:
pass
return successes >= w # Write succeeds if w servers acknowledge
Hinted handoff: When the “right” server is unavailable, write to another with a hint:
def write_with_hint(key, value, ring):
intended_server = ring.get_server(key)
if intended_server.is_healthy():
intended_server.put(key, value)
else:
# Store with hint on another server
backup = ring.get_next_healthy_server(key)
backup.put_with_hint(key, value, intended_server)
When the intended server recovers, it receives the hinted data.
8.3 Rebalancing Strategies
When servers are added, data must be redistributed:
Lazy rebalancing: Data moves on access.
def get_lazy(key):
new_server = ring.get_server(key)
value = new_server.get(key)
if value is None:
# Check old servers (before rebalancing)
for old_server in get_previous_servers(key):
value = old_server.get(key)
if value:
new_server.put(key, value) # Move on access
old_server.delete(key)
break
return value
Background rebalancing: Gradually move data in the background.
def rebalance_background(ring, new_server):
# Find all keys that should move to new_server
for existing_server in ring.servers:
keys_to_move = existing_server.scan_keys_for_server(new_server)
for key in keys_to_move:
# Throttle to avoid overwhelming the network
rate_limiter.wait()
value = existing_server.get(key)
new_server.put(key, value)
existing_server.delete(key)
9. Common Pitfalls
9.1 Hash Collision Handling
While rare, hash collisions can cause problems:
# Bad: Collision causes key loss
ring[(position, None)] = server # What if position exists?
# Good: Handle collisions
ring[(position, key_id)] = server # Include unique identifier
9.2 Ring Inconsistency
Different clients must see the same ring, or routing breaks:
# Bad: Local ring modification
ring.add_server(new_server) # Only this client knows!
# Good: Centralized configuration
ring_config = zookeeper.get("/ring/config")
ring = ConsistentHash.from_config(ring_config)
Use a coordination service (ZooKeeper, etcd, Consul) for ring configuration.
9.3 Hash Function Mismatch
Clients and servers must use the same hash function:
# Client uses MD5
client_pos = md5(key) % 2**32
# Server uses xxHash (WRONG!)
server_pos = xxhash(key) % 2**32
# Key will route to wrong server!
Specify the hash function explicitly in configuration.
9.4 Virtual Node Count
Too few virtual nodes: poor load balance. Too many virtual nodes: memory and lookup overhead.
Rule of thumb:
- 100-200 virtual nodes per server for good balance
- More for very large clusters (1000+ servers)
- Fewer for memory-constrained environments
9.5 Ignoring Rack/Zone Awareness
Replicas on the same rack fail together:
# Bad: Replicas might be on same rack
servers = ring.get_servers(key, num_replicas=3)
# Good: Ensure replicas are in different failure domains
servers = ring.get_servers_rack_aware(key, num_replicas=3)
def get_servers_rack_aware(self, key, num_replicas=3):
servers = []
racks_seen = set()
for candidate in self.ring.walk_from(key):
rack = self.server_to_rack[candidate]
if rack not in racks_seen:
servers.append(candidate)
racks_seen.add(rack)
if len(servers) >= num_replicas:
break
return servers
10. Performance Considerations
10.1 Lookup Performance
| Operation | Ring (Binary Search) | Jump Hash | Maglev | Rendezvous |
|---|---|---|---|---|
| Lookup | O(log(N×V)) | O(log N) | O(1) | O(N) |
| Add Server | O(V×log(N×V)) | O(1) | O(N×M) | O(1) |
| Remove Server | O(V×N×V) | N/A* | O(N×M) | O(1) |
| Memory | O(N×V) | O(1) | O(M) | O(N) |
*Jump hash only supports removing from the end.
10.2 When to Use What
Standard consistent hashing ring:
- General-purpose distributed systems
- Need to add/remove arbitrary servers
- Need weighted distribution
Jump consistent hashing:
- Numbered shards (shard 0, 1, 2, …)
- Add-only server growth
- Memory-constrained environments
Maglev hashing:
- Network load balancers
- Need O(1) lookup
- Can afford table rebuild on changes
Rendezvous hashing:
- Simple implementation needed
- Small number of servers
- Stateless clients
10.3 Caching Ring State
Ring computation can be cached:
class CachedConsistentHash:
def __init__(self, ring, cache_size=10000):
self.ring = ring
self.cache = LRUCache(cache_size)
def get_server(self, key):
if key in self.cache:
return self.cache[key]
server = self.ring.get_server(key)
self.cache[key] = server
return server
def invalidate_cache(self):
# Called when ring changes
self.cache.clear()
For stable rings, this dramatically reduces lookup overhead.
11. Consistent Hashing in Practice
11.1 Database Sharding
Consistent hashing determines which shard holds each key:
class ShardedDatabase:
def __init__(self, shards):
self.ring = ConsistentHash()
for shard in shards:
self.ring.add_server(shard)
def get(self, key):
shard = self.ring.get_server(key)
return shard.get(key)
def put(self, key, value):
shard = self.ring.get_server(key)
shard.put(key, value)
This enables horizontal scaling: add shards to increase capacity.
11.2 Session Affinity
Web applications often need session stickiness:
def route_request(request):
# Hash session ID to get consistent server
session_id = request.cookies.get('session_id')
if session_id:
return ring.get_server(session_id)
else:
# New session: pick random server
return random.choice(servers)
11.3 Distributed Rate Limiting
Rate limit across a cluster using consistent hashing:
def check_rate_limit(user_id):
# User's rate limit state lives on a specific server
server = ring.get_server(user_id)
return server.check_rate_limit(user_id)
This ensures all requests from a user go to the same rate limiter.
11.4 Distributed Locking
Assign locks to servers using consistent hashing:
def acquire_lock(resource_id):
lock_server = ring.get_server(resource_id)
return lock_server.acquire(resource_id)
Lock conflicts are handled by a single server, simplifying coordination.
12. Debugging Consistent Hashing Systems
When consistent hashing goes wrong, it can be challenging to diagnose. Here are the most common issues and how to debug them.
12.1 Detecting Uneven Load
Uneven load distribution is the most common problem:
def diagnose_load_distribution(ring, sample_keys, expected_ratio=1.5):
"""Check if load is distributed evenly across servers."""
server_counts = defaultdict(int)
for key in sample_keys:
server = ring.get_server(key)
server_counts[server] += 1
counts = list(server_counts.values())
avg = sum(counts) / len(counts)
max_count = max(counts)
min_count = min(counts)
print(f"Average keys per server: {avg:.1f}")
print(f"Max/Min ratio: {max_count/min_count:.2f}")
print(f"Coefficient of variation: {statistics.stdev(counts)/avg:.3f}")
# Flag servers with disproportionate load
for server, count in server_counts.items():
if count > avg * expected_ratio:
print(f"WARNING: {server} has {count} keys ({count/avg:.2f}x average)")
if count < avg / expected_ratio:
print(f"WARNING: {server} has only {count} keys ({count/avg:.2f}x average)")
return server_counts
Run this diagnostic with production-like keys to identify hot spots.
12.2 Visualizing the Ring
Visual inspection often reveals problems invisible in logs:
def visualize_ring(ring, width=100):
"""Print an ASCII visualization of server positions on the ring."""
max_hash = 2**32
scale = width / max_hash
# Collect all positions
positions = []
for server, vnodes in ring.virtual_nodes.items():
for pos in vnodes:
positions.append((pos, server))
positions.sort()
# Create visualization
line = ['.'] * width
for pos, server in positions:
idx = int(pos * scale)
if idx < width:
line[idx] = server[0].upper() # First letter of server name
print("Ring visualization (servers as letters):")
print(''.join(line))
# Show gaps
prev_pos = positions[-1][0] - max_hash
max_gap = 0
max_gap_pos = 0
for pos, server in positions:
gap = pos - prev_pos
if gap > max_gap:
max_gap = gap
max_gap_pos = pos
prev_pos = pos
print(f"\nLargest gap: {max_gap/max_hash*100:.2f}% of ring at position {max_gap_pos}")
Large gaps indicate areas where one server handles a disproportionate range.
12.3 Tracing Key Routes
When a specific key routes incorrectly, trace its path:
def trace_key_route(key, ring, verbose=True):
"""Trace how a key is routed through the ring."""
key_hash = ring.hash_function(key)
if verbose:
print(f"Key: {key}")
print(f"Hash: {key_hash} (0x{key_hash:08x})")
print(f"Ring position: {key_hash / 2**32 * 100:.4f}%")
# Find the server using binary search
index = ring.find_position(key_hash)
server_pos, server = ring.positions[index]
if verbose:
print(f"Assigned to: {server} at position {server_pos}")
# Show nearby positions
print("\nNearby ring positions:")
start = max(0, index - 2)
end = min(len(ring.positions), index + 3)
for i in range(start, end):
pos, srv = ring.positions[i]
marker = " <<" if i == index else ""
print(f" {pos}: {srv}{marker}")
return server
12.4 Detecting Ring Inconsistencies
Ensure all clients see the same ring:
def check_ring_consistency(ring_configs):
"""Compare ring configurations across multiple clients/servers."""
reference = None
for node_name, config in ring_configs.items():
ring = ConsistentHash.from_config(config)
if reference is None:
reference = (node_name, ring)
continue
ref_name, ref_ring = reference
# Compare server lists
if set(ring.servers) != set(ref_ring.servers):
print(f"SERVER MISMATCH: {node_name} vs {ref_name}")
print(f" Only in {node_name}: {set(ring.servers) - set(ref_ring.servers)}")
print(f" Only in {ref_name}: {set(ref_ring.servers) - set(ring.servers)}")
# Compare virtual node counts
for server in ring.servers:
if ring.get_weight(server) != ref_ring.get_weight(server):
print(f"WEIGHT MISMATCH: {server}")
print(f" {node_name}: {ring.get_weight(server)}")
print(f" {ref_name}: {ref_ring.get_weight(server)}")
# Test sample keys
test_keys = [f"test-key-{i}" for i in range(1000)]
misroutes = 0
for key in test_keys:
if ring.get_server(key) != ref_ring.get_server(key):
misroutes += 1
if misroutes > 0:
print(f"ROUTING MISMATCH: {misroutes}/{len(test_keys)} keys route differently")
12.5 Monitoring Health Metrics
Essential metrics for consistent hashing systems:
class ConsistentHashMetrics:
def __init__(self, ring):
self.ring = ring
self.stats = defaultdict(lambda: {"requests": 0, "bytes": 0, "latency_sum": 0})
def record_request(self, key, bytes_transferred, latency_ms):
server = self.ring.get_server(key)
self.stats[server]["requests"] += 1
self.stats[server]["bytes"] += bytes_transferred
self.stats[server]["latency_sum"] += latency_ms
def get_report(self):
report = []
total_requests = sum(s["requests"] for s in self.stats.values())
for server, stats in sorted(self.stats.items()):
pct = stats["requests"] / total_requests * 100 if total_requests > 0 else 0
avg_latency = stats["latency_sum"] / stats["requests"] if stats["requests"] > 0 else 0
report.append({
"server": server,
"requests": stats["requests"],
"request_pct": pct,
"bytes": stats["bytes"],
"avg_latency_ms": avg_latency
})
return report
Key metrics to monitor:
- Request distribution: Should be proportional to server weights
- Latency by server: High latency may indicate overload
- Cache hit rates: Per-server to detect cold servers after rebalancing
- Data size distribution: Some servers may hold larger values
13. Consistent Hashing in Different Languages
13.1 Go Implementation
Go’s strong concurrency support makes it ideal for distributed systems:
package consistenthash
import (
"hash/crc32"
"sort"
"strconv"
"sync"
)
type Ring struct {
mu sync.RWMutex
nodes map[uint32]string
sorted []uint32
replicas int
}
func New(replicas int) *Ring {
return &Ring{
nodes: make(map[uint32]string),
replicas: replicas,
}
}
func (r *Ring) Add(node string) {
r.mu.Lock()
defer r.mu.Unlock()
for i := 0; i < r.replicas; i++ {
hash := crc32.ChecksumIEEE([]byte(strconv.Itoa(i) + node))
r.nodes[hash] = node
r.sorted = append(r.sorted, hash)
}
sort.Slice(r.sorted, func(i, j int) bool {
return r.sorted[i] < r.sorted[j]
})
}
func (r *Ring) Get(key string) string {
r.mu.RLock()
defer r.mu.RUnlock()
if len(r.sorted) == 0 {
return ""
}
hash := crc32.ChecksumIEEE([]byte(key))
idx := sort.Search(len(r.sorted), func(i int) bool {
return r.sorted[i] >= hash
})
if idx >= len(r.sorted) {
idx = 0
}
return r.nodes[r.sorted[idx]]
}
13.2 Rust Implementation
Rust’s ownership model prevents common concurrency bugs:
use std::collections::BTreeMap;
use std::hash::{Hash, Hasher};
use std::collections::hash_map::DefaultHasher;
pub struct ConsistentHash {
ring: BTreeMap<u64, String>,
replicas: usize,
}
impl ConsistentHash {
pub fn new(replicas: usize) -> Self {
ConsistentHash {
ring: BTreeMap::new(),
replicas,
}
}
fn hash<T: Hash>(t: &T) -> u64 {
let mut hasher = DefaultHasher::new();
t.hash(&mut hasher);
hasher.finish()
}
pub fn add(&mut self, node: &str) {
for i in 0..self.replicas {
let key = format!("{}:{}", node, i);
let hash = Self::hash(&key);
self.ring.insert(hash, node.to_string());
}
}
pub fn remove(&mut self, node: &str) {
for i in 0..self.replicas {
let key = format!("{}:{}", node, i);
let hash = Self::hash(&key);
self.ring.remove(&hash);
}
}
pub fn get(&self, key: &str) -> Option<&String> {
if self.ring.is_empty() {
return None;
}
let hash = Self::hash(&key);
// Find the first node with hash >= key's hash
self.ring.range(hash..).next()
.or_else(|| self.ring.iter().next())
.map(|(_, node)| node)
}
}
13.3 Java Implementation
Enterprise systems often use Java with its mature ecosystem:
import java.util.SortedMap;
import java.util.TreeMap;
import java.security.MessageDigest;
public class ConsistentHash<T> {
private final int replicas;
private final SortedMap<Long, T> ring = new TreeMap<>();
public ConsistentHash(int replicas) {
this.replicas = replicas;
}
public void add(T node) {
for (int i = 0; i < replicas; i++) {
long hash = hash(node.toString() + ":" + i);
ring.put(hash, node);
}
}
public void remove(T node) {
for (int i = 0; i < replicas; i++) {
long hash = hash(node.toString() + ":" + i);
ring.remove(hash);
}
}
public T get(String key) {
if (ring.isEmpty()) {
return null;
}
long hash = hash(key);
// Find the first entry with hash >= key's hash
SortedMap<Long, T> tailMap = ring.tailMap(hash);
Long nodeHash = tailMap.isEmpty() ? ring.firstKey() : tailMap.firstKey();
return ring.get(nodeHash);
}
private long hash(String key) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] digest = md.digest(key.getBytes());
return ((long)(digest[3] & 0xFF) << 24) |
((long)(digest[2] & 0xFF) << 16) |
((long)(digest[1] & 0xFF) << 8) |
((long)(digest[0] & 0xFF));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
14. History and Evolution
14.1 Origins at Akamai
Consistent hashing was invented in 1997 by David Karger and colleagues at MIT, originally to solve web caching problems at Akamai. The insight was that traditional hashing schemes couldn’t handle the dynamic nature of CDN edge servers—nodes join and leave frequently, and the system needed to continue operating smoothly.
The original paper, “Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web,” laid the theoretical foundations that still guide implementations today.
14.2 Amazon Dynamo
Amazon’s Dynamo paper (2007) brought consistent hashing to mainstream distributed databases. Key innovations included:
- Virtual nodes: Solving the load balance problem with replicated ring positions
- Preference lists: Extending beyond a single responsible node to replica sets
- Sloppy quorum: Allowing writes to proceed when some nodes are unavailable
- Hinted handoff: Ensuring data reaches its intended location eventually
Dynamo’s design influenced DynamoDB, Cassandra, Riak, and countless other systems.
14.3 Maglev at Google
Google’s Maglev paper (2016) introduced a new approach optimized for network load balancing. The key insight was that load balancers need O(1) lookup (achieved via lookup tables) more than they need minimal disruption (since connection tracking handles in-flight requests anyway).
14.4 Modern Variations
Recent innovations include:
- Bounded-load consistent hashing: Caps the load on any server, sacrificing some consistency for better balance
- Multi-probe consistent hashing: Multiple hash probes reduce variance without virtual nodes
- Consistent hashing with bounded loads: Google’s approach combining load balancing with consistency
15. War Stories and Real-World Lessons
15.1 The Hot Partition Problem
A social media platform experienced severe degradation when a viral post caused millions of requests for the same key. The consistent hashing ring dutifully routed all requests to a single server, which promptly buckled under the load.
The solution involved multiple strategies:
def get_with_hot_key_handling(key):
"""Handle hot keys by spreading across replicas."""
if is_hot_key(key):
# Add randomness to spread load
suffix = random.randint(0, NUM_HOT_REPLICAS - 1)
effective_key = f"{key}:hot:{suffix}"
server = ring.get_server(effective_key)
# Try primary replicas first
value = server.get(key)
if value is None:
# Fall back to original server
server = ring.get_server(key)
value = server.get(key)
return value
else:
return ring.get_server(key).get(key)
def is_hot_key(key):
"""Detect hot keys using a counting bloom filter or local stats."""
return hot_key_detector.is_hot(key)
Alternatively, use a small in-memory cache in front of the consistent hash:
class HotKeyCache:
def __init__(self, ring, hot_cache_size=1000):
self.ring = ring
self.hot_cache = LRUCache(hot_cache_size)
self.access_counts = defaultdict(int)
def get(self, key):
# Check hot cache first
if key in self.hot_cache:
return self.hot_cache[key]
# Get from normal path
server = self.ring.get_server(key)
value = server.get(key)
# Track access and potentially cache
self.access_counts[key] += 1
if self.access_counts[key] > HOT_THRESHOLD:
self.hot_cache[key] = value
return value
15.2 The Phantom Server
A cluster experienced mysterious data loss after a network partition healed. Investigation revealed that during the partition, two halves of the cluster had independently decided to remove “unreachable” servers from their rings. When connectivity restored, each half had data that the other expected to be elsewhere.
The lesson: ring configuration changes must go through a consensus mechanism. Never let individual nodes unilaterally modify the ring topology.
class SafeRingManager:
def __init__(self, coordination_service):
self.zk = coordination_service
self.ring = ConsistentHash()
self.watch_ring_changes()
def watch_ring_changes(self):
"""Subscribe to ring configuration changes."""
@self.zk.watch("/ring/servers")
def on_change(servers):
self.ring = ConsistentHash()
for server in servers:
config = self.zk.get(f"/ring/servers/{server}")
self.ring.add_server(server, weight=config.weight)
def propose_remove_server(self, server):
"""Propose server removal through consensus."""
# Don't directly modify - let consensus decide
self.zk.create(f"/ring/proposals/remove-{server}",
data={"server": server, "reason": "unhealthy"})
15.3 The Slow Migration
A database migration used lazy rebalancing to move data to new shards. After weeks, significant data remained unmigrated because some keys were rarely accessed. The long tail of cold data can take indefinitely to migrate with lazy approaches.
The hybrid solution combined lazy and proactive migration:
class HybridMigration:
def __init__(self, old_ring, new_ring):
self.old_ring = old_ring
self.new_ring = new_ring
self.migrated = set()
def get(self, key):
"""Lazy migration on read."""
new_server = self.new_ring.get_server(key)
if key not in self.migrated:
value = new_server.get(key)
if value is None:
# Migrate on access
old_server = self.old_ring.get_server(key)
value = old_server.get(key)
if value:
new_server.put(key, value)
self.migrated.add(key)
else:
value = new_server.get(key)
return value
def background_migrate(self, batch_size=1000):
"""Proactive migration of cold data."""
for old_server in self.old_ring.servers:
for key in old_server.scan_keys(batch_size):
if key not in self.migrated:
new_server = self.new_ring.get_server(key)
if new_server != old_server:
value = old_server.get(key)
new_server.put(key, value)
self.migrated.add(key)
rate_limiter.wait() # Don't overwhelm the system
15.4 Clock Skew Chaos
A distributed cache used timestamps to determine data freshness. Clock skew between servers caused newer data to be overwritten by older data during replication. The consistent hashing was correct, but the conflict resolution was broken.
Use logical clocks or vector clocks instead of wall clocks:
class LamportTimestamp:
def __init__(self):
self.counter = 0
def increment(self):
self.counter += 1
return self.counter
def update(self, received_timestamp):
self.counter = max(self.counter, received_timestamp) + 1
return self.counter
class VectorClock:
def __init__(self, node_id, num_nodes):
self.node_id = node_id
self.clock = [0] * num_nodes
def increment(self):
self.clock[self.node_id] += 1
return self.clock.copy()
def update(self, received_clock):
for i in range(len(self.clock)):
self.clock[i] = max(self.clock[i], received_clock[i])
self.clock[self.node_id] += 1
def compare(self, other):
"""Returns: -1 (before), 0 (concurrent), 1 (after)"""
less = any(s < o for s, o in zip(self.clock, other))
greater = any(s > o for s, o in zip(self.clock, other))
if less and not greater:
return -1
elif greater and not less:
return 1
else:
return 0 # Concurrent - need application-level resolution
16. Summary
Consistent hashing is a foundational algorithm for distributed systems:
- Minimal disruption: Adding or removing servers moves only K/N keys
- Load balance: Virtual nodes ensure even distribution
- Scalability: Supports thousands of servers efficiently
- Flexibility: Handles heterogeneous servers, replication, and failures
Key takeaways:
- Use virtual nodes (100-200 per server) for load balance
- Choose the right hash function: Fast, uniform, deterministic
- Consider alternatives: Jump hash for numbered shards, Maglev for O(1) lookup
- Handle failures gracefully: Health checks, sloppy quorum, hinted handoff
- Maintain ring consistency: Use a coordination service
- Monitor and debug: Track load distribution, visualize the ring, compare configurations
From DynamoDB to Cassandra to your local Memcached cluster, consistent hashing enables the distributed systems that power the modern internet. Understanding it deeply transforms how you architect scalable systems.
The elegance of consistent hashing lies in its simplicity: by mapping both servers and keys to the same space, it achieves minimal disruption through pure geometry. That’s the kind of algorithm that makes you appreciate computer science.