Format-Preserving Encryption: The FFX Mode, Rank-Encipher-Unrank, and Legacy Database Protection
A technical deep dive into FPE: the Feistel-based FFX mode with AES, the rank-encipher-unrank construction, and practical applications in encrypting legacy databases and tokenization systems without breaking schemas.
Contents
Most encryption schemes expand the plaintext. AES in CBC mode adds padding and an IV. RSA-OAEP adds hundreds of bytes of overhead. Authenticated encryption adds a MAC tag. This expansion is fine for files and network streams, but it is a showstopper for legacy systems. Consider a credit card number: it is exactly 16 decimal digits, stored in a database column of type CHAR(16). If you encrypt it with AES-256-CBC and Base64-encode the result, you get a 44-character string that won’t fit in the column. If you truncate to fit, you lose the ability to decrypt. If you alter the schema, every application that touches that column—and in a mainframe banking system, there may be hundreds—must be updated, tested, and redeployed. The cost and risk of schema changes in legacy environments are often the primary barrier to adopting encryption.
Format-preserving encryption (FPE) solves this problem by encrypting a plaintext into a ciphertext of exactly the same format. A 16-digit decimal number encrypts to another 16-digit decimal number. A 9-character alphanumeric string encrypts to another 9-character alphanumeric string. The ciphertext looks exactly like a valid plaintext of the given format, so it passes all existing application-level validation (Luhn checks, format masks, character-set constraints). The database schema, the application code, the reporting queries—none of them need to change.
This article covers the cryptographic machinery behind FPE: the rank-encipher-unrank paradigm, the Feistel-based FFX mode standardized by NIST (SP 800-38G), the security analysis that makes unbalanced Feistel networks secure for small domains, and the practical applications in payment tokenization and legacy database encryption.
1. The Rank-Encipher-Unrank Paradigm
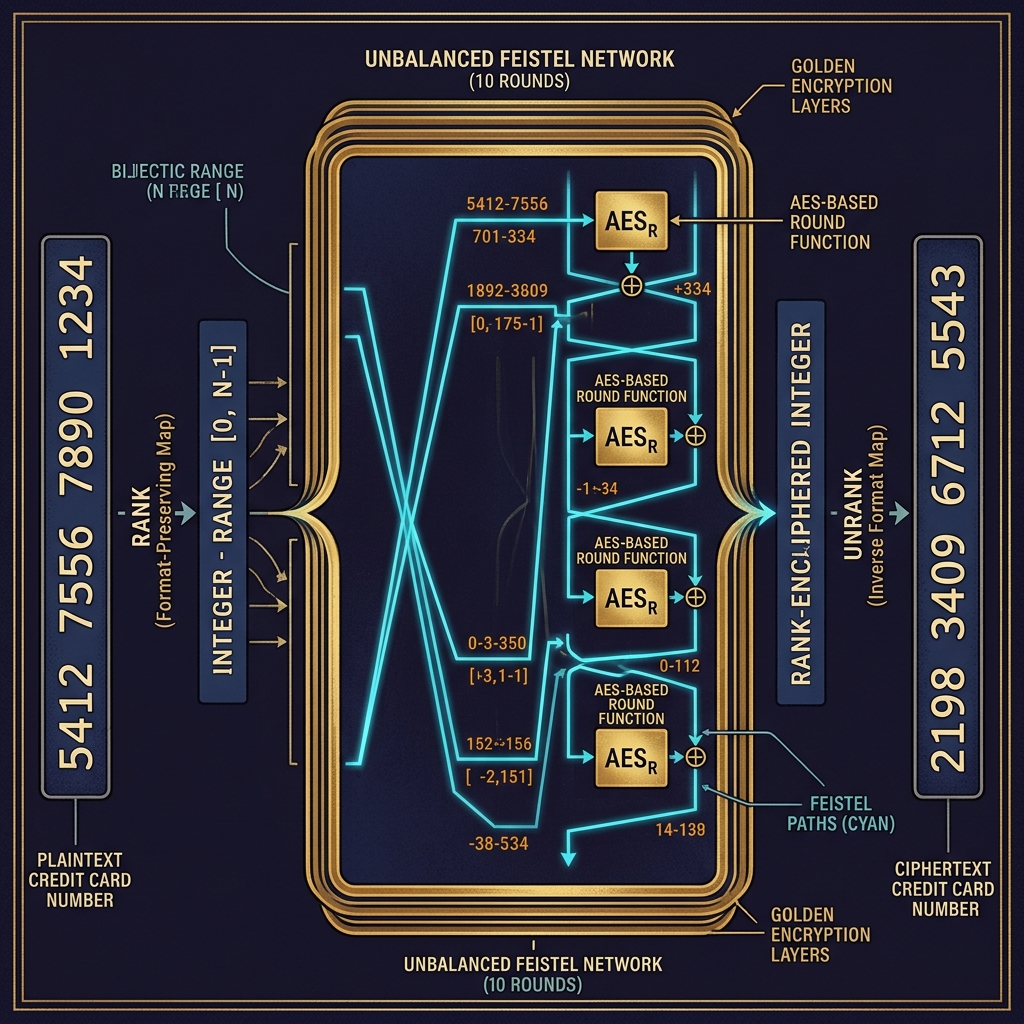
The fundamental idea of FPE is to reduce the problem of encrypting arbitrary-format data to the problem of encrypting integers in a range ([0, N-1]). This is accomplished by three functions:
- Rank: A bijection from the set of all valid plaintexts of the given format to the integer range ([0, N-1]), where (N) is the number of valid plaintexts. For example, a 16-digit decimal number has (N = 10^{16}) possible values, and the rank function is simply the identity (the string “4532…” interpreted as the integer 4532…).
- Encipher: A pseudorandom permutation (PRP) on ([0, N-1])—that is, a keyed permutation that is indistinguishable from a truly random permutation. This is the cryptographic core.
- Unrank: The inverse of rank, mapping the enciphered integer back to a formatted string.
The composition (\text{Unrank} \circ \text{Encipher} \circ \text{Rank}) is a format-preserving encryption scheme. The hard part is constructing an efficient enciphering algorithm for arbitrary (N), especially when (N) is not a power of 2 (so we cannot simply use a block cipher like AES directly).
2. The Feistel Network: From Luby-Rackoff to FFX
2.1 Balanced Feistel and the Luby-Rackoff Theorem
A balanced Feistel network on domain ({0,1}^{2n}) splits the input into left and right halves ((L_0, R_0)), each of (n) bits, and iterates for (r) rounds:
[ L*{i+1} = R_i, \quad R*{i+1} = Li \oplus F{K_i}(R_i) ]
where (F_{K_i}) is a round function keyed by (K_i) (typically derived from the master key via a key schedule). The output after (r) rounds is ((L_r, R_r)).
The Luby-Rackoff theorem (1988) states that a 3-round balanced Feistel with independent pseudorandom round functions is a pseudorandom permutation (secure against chosen-plaintext attacks), and a 4-round construction is a strong pseudorandom permutation (secure against chosen-ciphertext attacks). This theorem is the foundation for the security of Feistel-based encryption, including DES (16 rounds) and the FFX modes.
2.2 Unbalanced Feistel for Odd-Sized Domains
The challenge for FPE is that the domain size (N) is rarely a perfect square (which would allow splitting into two halves of equal size for a balanced Feistel). For instance, (N = 10^{16}) is not of the form (2^{2n}). The solution is an unbalanced Feistel network, where the left and right halves have different sizes.
In an unbalanced Feistel on domain ([0, N-1]), the input is split into two strings of lengths (a) and (b) bits (or, more generally, decomposed as (x = L \cdot M + R) where (L \in [0, \lfloor N/M \rfloor]) and (R \in [0, M-1]) for some chosen radix (M)). The round function operates on the larger of the two halves, and the halves are swapped (with appropriate adjustments for the size mismatch). After sufficiently many rounds, the result is a pseudorandom permutation on the full domain.
The security analysis of unbalanced Feistel networks was developed in a series of papers by Bellare, Rogaway, Morris, and others, culminating in the FFX mode (Format-preserving, Feistel-based mode, where X designates the specific variant).
3. The FFX Mode Family
NIST SP 800-38G (2016) standardizes two FPE modes: FF1 and FF3. (FF2 was withdrawn due to a security issue, and FF3-1 is a patched version of FF3.)
3.1 FF1: The General-Purpose Workhorse
FF1 works on any radix (\text{radix} \in [2, 2^{16}]) and any input length (\text{len} \in [2, \text{minlen} \ldots \text{maxlen}]). In practice, radix is 10 for decimal, 26 for alphabetic, 36 for alphanumeric, and 62 for alphanumeric-case-sensitive.
The FF1 structure is a 10-round unbalanced Feistel network. The input string (X) of length (n) over alphabet of size (\text{radix}) is split into (A = X[0 \ldots u-1]) and (B = X[u \ldots n-1]) where (u = \lfloor n/2 \rfloor). In each round (i):
- The round function derives a pseudorandom string (R) by encrypting a formatted block (containing (B), the round number (i), and a tweak (T) if present) under AES-128 or AES-256: (R = \text{AES}_K(\text{format}(B, i, T))).
- The string (R) is interpreted as a number in base (\text{radix}) of the appropriate length and added (modulo (\text{radix}^{|A|})) to (A).
- (A) and (B) are swapped.
After 10 rounds, the halves are concatenated. The result is a ciphertext of exactly the same length and radix as the plaintext.
The AES call in step 1 is the only cryptographic operation per round. With 10 rounds and a 128-bit AES, the per-encryption cost is roughly 10 AES block cipher calls, which is fast enough for bulk tokenization (hundreds of thousands of tokens per second on a modern CPU).
3.2 The Role of the Tweak
FF1 supports an optional tweak—additional authenticated data that is not encrypted but that affects the ciphertext. In tokenization applications, the tweak is typically a token type identifier or a unique transaction ID. The tweak ensures that the same plaintext encrypts to different ciphertexts in different contexts, preventing cross-context correlation attacks. Importantly, the tweak must be known at decryption time (it is not secret, but it must be authentic).
3.3 FF3 and FF3-1: The Shorter Variant
FF3 was designed for smaller domains (shorter plaintexts). It uses an 8-round unbalanced Feistel with a slightly different splitting rule. In 2017, Durak and Vaudenay discovered a devastating attack on FF3: given roughly (2^{22}) chosen-plaintext queries, an attacker could recover the key. The vulnerability stemmed from the small number of rounds (8) combined with the small domain size, which made the Feistel network’s mixing insufficient.
FF3-1 (2020) patches this by increasing the number of rounds to 10 (matching FF1) and by modifying the round counter formatting to prevent a related-key attack. The fix is minimal but effective: the additional rounds push the data complexity of any known attack beyond the birthday bound of the domain size, making it infeasible.
3.4 The NIST Standardization and Its Importance
The standardization of FF1 and FF3-1 by NIST was pivotal for industry adoption. Before SP 800-38G, FPE was a collection of proprietary algorithms (Voltage Security’s FPE, RSA’s BPS, HP’s FPE for database encryption) that lacked peer-reviewed security analysis. NIST standardization brought FPE into the mainstream, enabling it to be used in FIPS 140-2 validated modules and in regulated environments (PCI DSS for payment card data, HIPAA for healthcare).
4. FF1 Encryption Walkthrough: A Concrete Trace
To make the FF1 specification concrete, let’s trace through the encryption of a 16-digit credit card number “5378123498765432” with a 128-bit AES key and no tweak. This walkthrough follows the exact algorithm from NIST SP 800-38G.
Setup Parameters
Plaintext X = "5378123498765432"
radix = 10 (decimal digits)
n = 16 (length)
u = floor(n/2) = 8
v = n - u = 8
The input is split into A = X[0..7] = “53781234” and B = X[8..15] = “98765432”.
Round 0 (First Half of Round 1 in NIST Notation)
FF1 uses a numbering convention where the first “round” operates on B to modify A, and the second operates on A to modify B. The round function constructs an input block for AES:
P = [vers] || [method] || [addition] || [radix]^3 || [n]^3 || [tweak_len]^4 || [T] || [i] || [B]
Where:
vers= 0x01 (version byte)method= 0x01 (FF1)addition= 0x01 (no addition operation)radix= 10 encoded in 3 bytesn= 16 encoded in 3 bytestweak_len= 0 (no tweak)i= round number (0-indexed)B= current right half as a byte string
The block P is encrypted under AES: R = AES_K(P). The first u bytes of R are interpreted as an integer r in base radix (i.e., as an 8-digit decimal number). Let’s say r = 48172653 (pseudorandom, determined by AES output).
Now we compute the new A:
C = A + r (mod radix^u) = 53781234 + 48172653 (mod 10^8)
= 101953887 (mod 10^8) = 01953887
But wait — A and C must have exactly u digits. If C has fewer than u digits (leading zeros), we pad with leading zeros. So the new A is “01953887”.
Then we swap: new B = old A = “53781234”, new A = C = “01953887”.
Rounds 1-9
Each subsequent round follows the same pattern, alternating which half is modified. After round 1 (now operating on the other half):
Current state: A = "01953887", B = "53781234"
Construct P with B as the rightmost bytes, i = 1
R = AES_K(P) -> r = 90512367 (example)
C = A + r (mod 10^8) = 01953887 + 90512367 = 92466254
Swap: A = "53781234", B = "92466254"
This continues for 10 rounds total. The even rounds (0, 2, 4, 6, 8) operate on B to modify A; the odd rounds (1, 3, 5, 7, 9) operate on A to modify B. After the final round, the halves are concatenated without a final swap:
After round 9: A = "29473810", B = "61938574" (example final values)
Ciphertext = A || B = "2947381061938574"
The ciphertext is exactly 16 decimal digits, preserving the format. Decryption runs the same rounds in reverse order, subtracting instead of adding.
Key Observations from the Trace
Several design decisions become apparent from this walkthrough:
The AES call is the only source of cryptographic strength. The modular addition is purely arithmetic and carries no security — it’s the Feistel structure combined with the pseudorandom round values that provides the permutation security.
The format block P is carefully constructed to prevent domain confusion. Every round uses a unique P (different round number i, different B value), so the AES outputs are independent across rounds. The version and method bytes prevent an attacker from using ciphertexts from one FPE variant to attack another.
The splitting rule
u = floor(n/2)handles both even and odd lengths. For odd n (e.g., 15-digit numbers), u = 7 and v = 8, so the halves are unbalanced. The round function handles this by usingufor the modular arithmetic regardless of which half is larger.Performance is deterministic. Exactly 10 AES calls per encryption, regardless of input. There is no iteration, no retry loop, no variable-time behavior. This makes FF1 suitable for constant-time implementation in HSMs.
5. The Security Bounds: Concrete Advantage Calculations
Understanding FPE security requires moving beyond the asymptotic Luby-Rackoff theorem to concrete bounds — how many queries can an adversary make before the distinguishing advantage becomes non-negligible?
The Hoang-Morris-Rogaway Bound
Hoang, Morris, and Rogaway (2012) proved that for an unbalanced Feistel network with r rounds on a domain of size N, the distinguishing advantage against a chosen-plaintext attacker making q queries is bounded by:
$$ \mathbf{Adv}^{prp}{\text{FF}}(q) \leq \frac{q^2}{2N} + \frac{q^2}{2 \cdot N^{r/2-1}} + \mathbf{Adv}^{prf}{\text{AES}}(q, t) $$
where:
- The first term (\frac{q^2}{2N}) is the birthday bound — inherent to any permutation on N elements (a truly random permutation also has collision probability q²/2N).
- The second term captures the Feistel-specific advantage, which decays exponentially with the number of rounds.
- The third term is the PRF advantage against AES.
Concrete Numbers for FF1 on Credit Cards
Let’s instantiate these bounds for FF1 on a 16-digit PAN:
N = 10^16 ≈ 2^53.15
q = 2^20 (about 1 million encryption queries)
r = 10 rounds
The birthday term is:
$$ \frac{(2^{20})^2}{2 \cdot 10^{16}} = \frac{2^{40}}{2 \cdot 10^{16}} \approx \frac{1.1 \times 10^{12}}{2 \times 10^{16}} = 5.5 \times 10^{-5} $$
The Feistel term (simplified from the HMR bound) is:
$$ \approx \frac{2^{40}}{2 \cdot (10^{16})^{4}} \approx \frac{10^{12}}{10^{64}} = 10^{-52} $$
which is negligible — the Feistel rounds contribute essentially nothing to the advantage at this query volume. So the overall advantage is dominated by the birthday bound: about 2^{-14.2} or roughly 0.0055%.
This means an attacker making 1 million chosen-plaintext queries has a distinguishing advantage of at most about 0.0055% — they can distinguish FF1 from a random permutation with probability only marginally better than 50%. For practical purposes, this is negligible. At q = 10^8 (100 million queries), the birthday bound rises to about 0.055%, still acceptable for most applications. Only at q ≈ 10^15 (close to sqrt(N)) does the bound approach 0.5, and at that point the attacker has collected a significant fraction of the codebook anyway.
The FF3 Failure in Concrete Terms
Why did 8-round FF3 fail? Plugging r = 8 into the bound gives a Feistel term of approximately q² / (2 * N^3). For N = 10^7 and q = 2^22 (the attack complexity):
$$ \frac{(2^{22})^2}{2 \cdot (10^7)^3} = \frac{2^{44}}{2 \cdot 10^{21}} \approx \frac{1.76 \times 10^{13}}{2 \times 10^{21}} = 8.8 \times 10^{-9} $$
The asymptotic bound says this should be negligible, but the attack succeeded because the concrete analysis of slide attacks revealed a structural weakness not captured by the generic HMR bound. The HMR bound assumes ideal round functions; the actual round functions in FF3 have algebraic structure (they are AES-based but the Feistel addition interacts with the radix structure) that the generic analysis does not model. This gap between generic bounds and practical attacks is a recurring theme in symmetric cryptography — the bounds are necessary conditions for security, not sufficient ones.
6. Beyond Feistel: Card Shuffling and Thorp Shuffle
Feistel networks are not the only way to construct a PRP on an arbitrary domain. An alternative approach, inspired by the physical act of shuffling a deck of cards, is the Thorp shuffle (Morris, Rogaway, and Stegers, 2009).
The Thorp shuffle works on a domain of size (N) represented as a sequence of (n) “cards,” each from a small alphabet (e.g., for (N = 10^{16}), we can represent the input as 16 cards, each a digit 0-9). The shuffle applies a sequence of pairwise swaps, where each swap exchanges two cards based on a pseudorandom bit derived from AES. After (O(n \log n)) swaps (or a constant number of rounds over the entire deck, analogous to a riffle shuffle), the permutation is indistinguishable from random.
The Thorp shuffle’s advantage over Feistel is its flexibility: it works naturally for any radix and any length, and its security analysis is clean (based on the mixing time of the underlying Markov chain). Its disadvantage is performance: (O(n \log n)) AES calls per encryption vs. Feistel’s (O(n)) calls, making it slower for long strings. For credit card numbers (16 digits), the Thorp shuffle is competitive; for larger strings, Feistel-based FF1 is usually preferred.
5. Security Analysis: What Could Go Wrong?
FPE security is subtle. The adversary’s goal is to distinguish the FPE scheme from a truly random permutation on the message space, or to recover plaintexts from ciphertexts without the key. Several attack vectors have been demonstrated:
Codebook attacks. If the message space is small (say, (N = 10^4) for a 4-digit PIN), an attacker can build a complete codebook by observing encryptions of all possible plaintexts (or by actively querying an encryption oracle). FPE cannot prevent this—it is inherent in the small domain. For small domains, FPE should be combined with rate limiting, monitoring, and application-level defenses. NIST recommends a minimum domain size of (10^6) for FF1 (roughly the size of a 6-digit numeric code or a 4-character alphanumeric code).
Round reduction attacks. As demonstrated by the FF3 attack, too few Feistel rounds allow statistical attacks that exploit incomplete diffusion. The minimum number of rounds for security at a given domain size is governed by the Luby-Rackoff bound generalized to unbalanced Feistel. For FF1, 10 rounds are sufficient for security up to the birthday bound (roughly (\sqrt{N}) queries).
Tweak misuse. If the tweak is not unique per encryption (e.g., reusing the same tweak for different plaintexts), the FPE scheme reduces to a deterministic encryption of the plaintext, and the adversary can detect equality of plaintexts across encryptions. This is not a break of the FPE primitive but a protocol-level misuse.
Side channels. FPE implementations must be constant-time and resistant to cache-timing attacks. The Feistel round function involves modular arithmetic on large integers, which in naive implementations can leak timing information correlated with the plaintext. Constant-time big-integer arithmetic is well-understood but must be applied meticulously.
6. Tokenization: The Killer App for FPE
Payment tokenization is the process of replacing a Primary Account Number (PAN, i.e., a credit card number) with a token that can be used in payment processing without exposing the actual card number. The token must pass the same format validations as the PAN (length, prefix, Luhn check digit), and it must be possible to detokenize (recover the original PAN) when the token reaches the payment processor or the card network.
There are two architectural approaches to tokenization:
Vault-based tokenization. A central “token vault” maintains a database mapping PANs to randomly generated tokens. Tokenization is a lookup; detokenization is a reverse lookup. This requires the vault to be online for every transaction, creating a scaling bottleneck and a single point of compromise (if the vault mapping is breached, all PANs are exposed).
FPE-based tokenization. The PAN is encrypted in-place using FPE with a key held securely (in an HSM). Tokenization is FPE encryption; detokenization is FPE decryption. No database mapping is needed. The key is the sole secret, and it can be protected using standard HSM key management practices (never leaving the HSM boundary).
The FPE approach is stateless, horizontally scalable, and avoids the vault-as-bottleneck problem. The tradeoff is that FPE-based tokens are linkable across merchants that use the same key (since the same PAN always tokenizes to the same token). This is addressed by including a merchant-specific tweak in the FPE encryption, so that the same PAN produces different tokens for different merchants, breaking cross-merchant tracking.
The major card networks (Visa, Mastercard) have deployed FPE-based tokenization (Visa Token Service and Mastercard Digital Enablement Service) at scale, processing billions of tokenized transactions per year. The underlying FPE is typically FF1 with AES-256, validated to FIPS 140-2 Level 3 in hardware HSMs.
7. Legacy Database Encryption: The Other Major Use Case
Beyond tokenization, FPE addresses the pervasive problem of encrypting data in legacy databases without changing the schema. A typical scenario: a healthcare organization wants to encrypt patient Social Security Numbers (9 digits, XXX-XX-XXXX format) in a production database that runs on an IBM mainframe with COBOL applications that have not been significantly modified since the 1980s. Altering the SSN column from CHAR(9) to VARCHAR(256) to accommodate AES-CBC ciphertexts would require modifying, recompiling, and regression-testing dozens of COBOL programs—a multi-year, multi-million-dollar project.
FPE encrypts SSNs to 9-digit numbers, preserving the schema. The COBOL programs continue to work, reading and writing what appear to be valid SSNs. The encryption and decryption are performed by a database proxy or a stored procedure that intercepts reads and writes, applying FPE transparently. This architectural pattern—a “crypto-shim” that mediates between legacy applications and their data—is the dominant deployment model for FPE in regulated industries.
The same pattern applies to date-of-birth fields, ZIP codes, employee IDs, and any other fixed-format sensitive data. The FPE key is stored in an HSM, and access to the key (and thus to the plaintext) is controlled by access policies enforced at the proxy layer.
8. Format-Preserving Hashing and the Broader Ecosystem
FPE is one member of a family of format-preserving cryptographic primitives. Format-preserving hashing (FPH) produces a deterministic, non-invertible format-preserving output, useful for pseudonymization where detokenization is never needed (e.g., anonymizing data for analytics). FPH can be constructed by applying FPE with a fixed key and then discarding the key—or, more efficiently, by using a keyed hash function combined with a Feistel-like structure where the round function is a hash rather than an encryption.
Format-preserving authenticated encryption adds integrity protection to FPE, producing a ciphertext that is slightly larger than the plaintext but still within a predictable format (e.g., a 16-digit PAN encrypts to a 19-digit token where the extra 3 digits are a MAC). This is an active research area; the NIST SP 800-38G modes do not provide authentication natively, and applications that need integrity must compose FPE with an external MAC, carefully managing the format constraints.
Order-preserving encryption (OPE), while not format-preserving in the strict sense, preserves the numerical order of plaintexts in the ciphertexts, enabling range queries on encrypted data. OPE leaks strictly more information than FPE (it reveals the order relation), but for applications like encrypted database indexes, this leakage is acceptable. The practical OPE schemes (Boldyreva et al., 2009, 2011) use similar Feistel-based techniques to FPE, adapted to preserve order instead of format.
9. Implementation Considerations and Pitfalls
Implementing FPE correctly requires attention to several subtle details:
Luhn digit preservation. Credit card numbers include a Luhn check digit (the last digit) that is a function of the preceding digits. If FPE is applied to the entire PAN, the ciphertext will likely have an invalid Luhn digit, causing validation failures. The standard approach is to exclude the Luhn digit from encryption (encrypt only the first 15 digits) and recompute the Luhn digit after encryption. This preserves both format and validity.
Character set encoding. For alphanumeric formats, the rank function must map character strings to integers unambiguously. The mapping must be consistent across platforms (EBCDIC vs. ASCII vs. UTF-8) and must handle case sensitivity correctly. The NIST standard specifies a simple lexicographic ordering (0-9, A-Z, a-z) for alphanumeric radices, but legacy systems may use different collations.
Performance optimization. The AES calls in FF1 are the performance bottleneck. For high-throughput tokenization (millions of tokens per second), hardware acceleration via AES-NI is essential. The FF1 format function (which constructs the AES input block from the round state) should be implemented to minimize data movement and avoid unnecessary copies.
Key management. FPE keys must be managed with the same rigor as any encryption key. For tokenization at scale, the key hierarchy typically includes a master key (in an HSM) that derives per-merchant or per-token-type keys via a KDF, enabling fine-grained access control and key rotation without re-encrypting all tokens.
10. The Security Proof Landscape and the FF3 Break
The security of FF1 and FF3-1 rests on reductions from the Luby-Rackoff theorem. For unbalanced Feistel networks, Hoang, Morris, and Rogaway (2012) proved security up to the birthday bound of sqrt(N) queries on a domain of size N. For FF1 with 10 rounds and a domain of size radix^n, the concrete security bound is approximately q^2 / (2 * radix^n) plus the PRF advantage of AES.
The FF3 vulnerability (Durak and Vaudenay, 2017) was a devastating slide attack: with 2^22 chosen-plaintext queries on a domain of 10^7, an attacker could recover the full key. The attack exploited the 8-round construction combined with FF3’s specific splitting rule. FF3-1 fixes this by increasing to 10 rounds and modifying the round counter formatting, breaking the algebraic structure the slide attack relied on. The broader lesson is that Feistel-based FPE demands conservative round counts; constant-factor gaps between asymptotic bounds and practical security can be cryptanalytically exploitable.
11. Format-Controlled Encryption Variants
Beyond basic format preservation, several related primitives extend the idea in useful directions. Prefix-preserving encryption maintains IP subnet structure in anonymized network traces, using Feistel variants where rounds operate only on the suffix while preserving the prefix deterministically. Tools like Crypto-PAn and tcpdpriv enable researchers to analyze traffic patterns aggregated by subnet without exposing individual endpoint identities.
Format-transforming encryption (FTE) makes ciphertext mimic a target protocol’s statistical profile for circumvention purposes. An FTE scheme can transform encrypted Tor traffic to resemble HTTP or Skype flows, evading deep packet inspection classifiers. FTE uses rank-encipher-unrank with different source and target formats, and has been deployed in Tor pluggable transports like meek and obfs4, as well as in steganographic file systems.
Datatype-preserving encryption extends FPE to structured data types: encrypting a JSON object to a valid JSON object of the same schema, or an XML document to a well-formed XML document. The rank function must efficiently map all valid schema instances to integers – a hard combinatorial problem when schemas include optional fields, variable-length arrays, and enumerated types. Research prototypes like Microsoft CrypTen demonstrate feasibility, but general structured-data FPE remains unstandardized.
13. Real-World Deployments and Case Studies
FPE’s commercial impact is best illustrated through specific deployments. Visa Token Service (VTS), launched in 2014, uses FF1-based FPE to tokenize Primary Account Numbers at scale. When a consumer adds a credit card to a mobile wallet (Apple Pay, Google Pay), the PAN is encrypted under a token service provider key using FF1 with AES-256. The resulting token preserves the 16-digit format and passes Luhn validation. VTS processes billions of tokenizations per year, with token generation latency under 10 ms, of which FPE encryption accounts for less than 1 microsecond per token thanks to AES-NI acceleration within HSMs.
Mastercard Digital Enablement Service (MDES) uses a similar FF1-based architecture, with the additional requirement that tokens be merchant-specific: the same PAN produces different tokens for different merchants. This is achieved by including a merchant identifier as the tweak in FF1, ensuring that cross-merchant tracking via token correlation is cryptographically impossible.
Voltage SecureData (acquired by Micro Focus, now OpenText) was one of the first commercial FPE products, predating the NIST standard. It used a proprietary Feistel-based construction (the “Voltage FPE” algorithm) that was later aligned with FF1 after SP 800-38G was published. Voltage’s FPE has been deployed in mainframe environments (IBM z/OS with COBOL applications), in Oracle and SQL Server databases via transparent data encryption plugins, and in Hadoop data lakes for format-preserving encryption of PII in big data pipelines.
AWS Database Encryption SDK (2023) introduced FPE support using FF1, enabling DynamoDB and RDS customers to encrypt sensitive columns without changing column types or breaking application-level validation. The SDK handles the rank-encipher-unrank transformation transparently, mapping application-level types (credit card numbers, SSNs, email addresses) to integer ranges and back.
The common thread across these deployments is that FPE’s value proposition is not primarily cryptographic but operational: it eliminates the schema migration that would otherwise be required to accommodate ciphertext expansion. In organizations where database schema changes require months of planning, testing, and compliance review, FPE reduces the time to deploy encryption from months to days.
14. Hardware Acceleration and Constant-Time Implementations
For high-throughput tokenization at scale – millions of tokens per second – software FPE implementations must be carefully optimized. The AES calls in FF1 are the dominant cost: each of the 10 rounds requires an AES encryption of a formatted block. With AES-NI instructions, a single AES-128 block encryption costs roughly 10-30 cycles, making the per-token cost roughly 100-300 cycles, or about 30-100 ns on a 3 GHz core. This enables 10-30 million tokens per second on a single core – sufficient for most payment processing volumes.
However, achieving this performance requires attention to several implementation details. The FF1 format function, which constructs the AES input block from the round state, must minimize data movement between registers. The modular arithmetic in the Feistel round (addition of the pseudorandom string to the plaintext half, modulo radix^|A|) must be implemented in constant time to avoid timing side channels that could leak information about the plaintext or the round keys.
For hardware security modules (HSMs), FPE is typically implemented within the HSM boundary, with the key material never leaving the secure cryptographic processor. PCI PTS HSM requirements mandate FPE implementations that are resistant to both timing and power side channels, which is achieved through constant-time big-integer arithmetic and, in some HSMs, dual-rail precharge logic at the hardware level.
An emerging concern is the interaction between FPE and speculative execution vulnerabilities. Because the Feistel round function involves data-dc14dc3 memory accesses (to S-box lookup tables if AES is implemented with tables) or data-dc14dc3 arithmetic (in constant-time bitslice AES), speculative execution can leak information about the plaintext through cache timing. The mitigation is to use bitslice AES (which eliminates table lookups) and to ensure that the Feistel addition is implemented with constant-time modular arithmetic, avoiding any secret-dependent branches or memory accesses.
Beyond speculative execution, another implementation challenge is the secure handling of intermediate values during the Feistel rounds. Each round produces a pseudorandom block from AES that is used to update one half of the plaintext. If this intermediate value is written to stack memory or spilled to the cache in a way that correlates with the plaintext, an attacker with access to memory side channels (e.g., via a co-located process exploiting cache timing or via physical memory probing) could potentially recover information about the plaintext or, in the worst case, about the round keys. Production FPE implementations in HSMs address this by keeping all intermediate Feistel state in registers, using register-only AES implementations and ensuring that the modular arithmetic never spills to memory. The Thales payShield HSM, for example, implements FF1 entirely within its secure cryptographic processor with no intermediate values ever leaving the secure boundary, achieving both FIPS 140-2 Level 3 and PCI PTS HSM certification for its FPE module.
16. Theoretical Foundations: The Rank Function in Depth
The rank-encipher-unrank paradigm reduces arbitrary-format encryption to integer-range encryption, but the rank function itself deserves deeper scrutiny. For a format defined by a regular expression or a context-free grammar, the rank function is essentially a bijection between the set of valid strings (the language of the grammar) and the integer range [0, N-1] where N is the number of valid strings.
For simple formats (fixed-length alphanumeric, fixed-length numeric), the rank function is straightforward string-to-integer conversion with a specified radix. For a 16-digit decimal number, rank(“4532…”) parses the string as the integer 4532… . For an 8-character alphanumeric string with radix 36 (0-9, A-Z), each character position contributes a digit in base 36, and the rank is the usual base-36 to decimal conversion.
For more complex formats, the rank function must account for variable-length components, optional characters, and inter-field dependencies. Consider a US phone number format: “(XXX) XXX-XXXX” where X is a digit 0-9 but with the constraint that the first digit of the area code cannot be 0 or 1. The number of valid phone numbers is 8 _ 10 _ 10 _ 8 _ 10 _ 10 _ 10 _ 10 _ 10 _ 10 = 6.4 _ 10^9 (factoring in the [2-9] constraint on the first digit of area code and exchange). The rank function must efficiently compute the integer index of a given phone number without iterating over all valid numbers – a combinatorial enumeration problem that becomes computationally expensive for formats with many constraints.
For formats defined by general regular expressions, computing the rank function is equivalent to counting the number of strings of each length accepted by a deterministic finite automaton (DFA), which can be done using matrix exponentiation in O(k^3 log n) time where k is the number of DFA states and n is the string length. This is efficient for small automata but becomes impractical for formats with hundreds of states. In practice, production FPE systems handle a curated set of common formats (credit card numbers, SSNs, dates, alphanumeric codes) with hand-optimized rank functions, rather than attempting general regular expression compilation.
18. Alternative Constructions: Thorp Shuffle and Cycle-Walking
While the Feistel-based FFX modes dominate practice, two alternative FPE constructions deserve mention for their different tradeoffs.
The Thorp shuffle (Morris, Rogaway, and Stegers, 2009) constructs a PRP on an arbitrary domain by modeling the encryption as a card shuffle. The domain of size N is represented as a sequence of n “cards,” each from a small alphabet (e.g., for N = 10^16, 16 cards each a digit 0-9). The shuffle applies a sequence of pairwise swaps, each determined by a pseudorandom bit derived from AES. After O(n log n) swaps – analogous to the mixing time of a riffle shuffle – the permutation is indistinguishable from random. The Thorp shuffle’s advantage over Feistel is flexibility: it works naturally for any radix and any length, and its security analysis is clean, based on the mixing time of the underlying Markov chain. Its disadvantage is performance: O(n log n) AES calls per encryption versus Feistel’s O(n), making it slower for long strings. For credit card numbers (16 digits), the Thorp shuffle is competitive; for longer strings, Feistel-based FF1 is preferred in practice.
Cycle-walking is a simpler but less efficient alternative: use a standard block cipher (AES) on the next power-of-two domain size larger than N, and if the ciphertext falls outside [0, N-1], re-encrypt until it does. The expected number of encryptions is at most 2 (since the probability of landing in the valid range is at least 1/2), but worst-case could be unbounded, and the deterministic nature of cycle-walking makes it vulnerable to timing analysis (the number of iterations reveals whether the intermediate ciphertext was in-range). Cycle-walking is used in some legacy systems but is not recommended for new designs.
The NIST selection of FFX for standardization reflected a judgment that the Feistel-based approach offered the best combination of security, performance, and flexibility. The Thorp shuffle was considered but deferred due to its higher per-encryption cost; cycle-walking was rejected due to its non-constant-time behavior. As FPE deployments grow, alternative constructions may be standardized, particularly for specialized domains where Feistel’s structure introduces undesirable properties (e.g., the even-odd structure of FF1’s splitting rule can interact badly with some format constraints).
19. Summary
Format-preserving encryption solves a problem that is more organizational than cryptographic: how to add confidentiality to data in systems that cannot be changed. The cryptographic core—the unbalanced Feistel network with AES-based round functions, as standardized in FF1 and FF3-1—is elegant and well-analyzed. The practical deployment in payment tokenization and legacy database encryption has made FPE one of the most commercially successful applications of symmetric cryptography beyond the standard file-and-connection encryption use cases.
The intellectual content of FPE lies in the generalization of the Luby-Rackoff construction to unbalanced, radix-mixed domains, and in the security analysis that bounds the distinguishing advantage as a function of the number of rounds, the domain size, and the number of queries. The practical content lies in the rank-encipher-unrank paradigm, which reduces arbitrary-format encryption to integer-range encryption, and in the engineering discipline of integrating FPE into legacy systems without disrupting their operation.
FPE is a reminder that cryptography serves real-world constraints, and that the most impactful cryptographic innovations are often those that adapt to existing systems rather than demanding that systems adapt to them. The rank-encipher-unrank paradigm is a design pattern as fundamental as the Feistel network itself: it modularizes the problem into format-specific ranking (a combinatorics problem) and integer-range encryption (a cryptographic problem), enabling each to be solved independently and composed. This separation of concerns is what makes FPE practical across the enormous diversity of legacy data formats.
The most significant open problem in FPE is not cryptographic but operational: how to manage FPE keys across an organization with hundreds of legacy applications, each with its own data format, key rotation schedule, and access control requirements. Centralized key management with format-aware policy enforcement – ensuring that the FPE key for SSNs is never used to encrypt credit card numbers, for instance – is the next frontier for FPE deployment at enterprise scale. As with all applied cryptography, the hard part is not the algorithm but the system around it.
The mathematically purest solution—encrypt everything with AES-GCM and redesign the schema—is often the least practical. FPE meets the legacy system where it is, adding security without demanding transformation. That pragmatism, combined with rigorous cryptographic analysis, is what makes FPE a quiet but essential part of the data protection landscape.