Garbage Collection Advanced: Incremental, Concurrent, Snapshot-at-the-Beginning, and Pauseless Collectors from Azul C4 to ZGC Colored Pointers
A deep exploration of advanced garbage collection algorithms that eliminate stop-the-world pauses — incremental marking, concurrent collection, the snapshot-at-the-beginning barrier, and the pauseless collectors that make Java viable for low-latency applications.
Contents
In 2005, Azul Systems shipped a custom Java Virtual Machine running on a custom 384-core processor with a custom garbage collector that promised something unheard-of: no stop-the-world pauses. While every other JVM on the market paused all application threads for hundreds of milliseconds (or seconds) to collect garbage, Azul’s C4 collector ran concurrently with the application, collecting garbage without ever stopping the mutator. The secret was a combination of hardware support (the Vega processor’s read barrier), algorithmic innovation (the “continuously concurrent compacting collector”), and a willingness to rethink every assumption about how garbage collection should work. Today, Azul’s pauseless vision is realized in mainstream JVMs: ZGC (Oracle) and Shenandoah (Red Hat) deliver sub-millisecond pause times on commodity hardware. This post explores the algorithms that make this possible.
1. The Stop-the-World Problem
Traditional garbage collectors — mark-sweep, mark-compact, copying collectors — share a fundamental problem: they require the mutator (the application) to be stopped while the collector identifies and reclaims garbage. The reason is that the collector needs a consistent view of the object graph. If the mutator modifies pointers while the collector is traversing the graph, the collector might miss live objects (causing premature reclamation and crashes) or fail to update pointers to moved objects (causing dangling references).
The simplest solution is to stop all mutator threads, perform the entire collection (mark all live objects, sweep or compact), and then resume the mutator. For small heaps, this is fast enough. For a 100 MB heap, a stop-the-world mark-sweep collection might take 10-50 milliseconds. For a 100 GB heap — common in modern server applications — it might take tens of seconds. During that time, the application is completely unresponsive. For a trading system processing orders at microsecond latencies, a 10-second pause is catastrophic.
The history of garbage collection research is largely the history of reducing or eliminating stop-the-world pauses. The progression has been: stop-the-world → generational (most objects die young, so collect only the young generation frequently) → incremental (break the collection into small slices, interleaved with mutator execution) → concurrent (run the collector alongside the mutator, using synchronization to maintain consistency) → pauseless (never stop the mutator at all).
2. The Tricolor Abstraction and the Consistency Problem
To understand concurrent collection, we need the tricolor abstraction for garbage collection, introduced by Dijkstra in 1978. Objects are colored:
White: Not yet visited by the collector. At the start of marking, all objects are white. At the end of marking, white objects are garbage and can be reclaimed.
Gray: Visited by the collector, but the collector hasn’t yet scanned the object’s fields (its outgoing pointers). Gray objects form the “frontier” of the marking wavefront.
Black: Visited by the collector, and all of the object’s fields have been scanned. Black objects are known to be reachable, and they point only to gray or black objects (in a consistent state).
The marking algorithm is simple: start with all roots (global variables, stack slots, registers) colored gray. Repeatedly pick a gray object, scan its fields (coloring any white objects gray), and color the scanned object black. When there are no more gray objects, marking is complete, and remaining white objects are garbage.
The problem with concurrent marking is that the mutator can violate the tricolor invariant while the collector is running. If the mutator stores a reference to a white object into a field of a black object (which the collector has already scanned), the collector won’t see that reference, and the white object will be incorrectly collected as garbage. This is called the “lost object problem.”
There are two families of solutions:
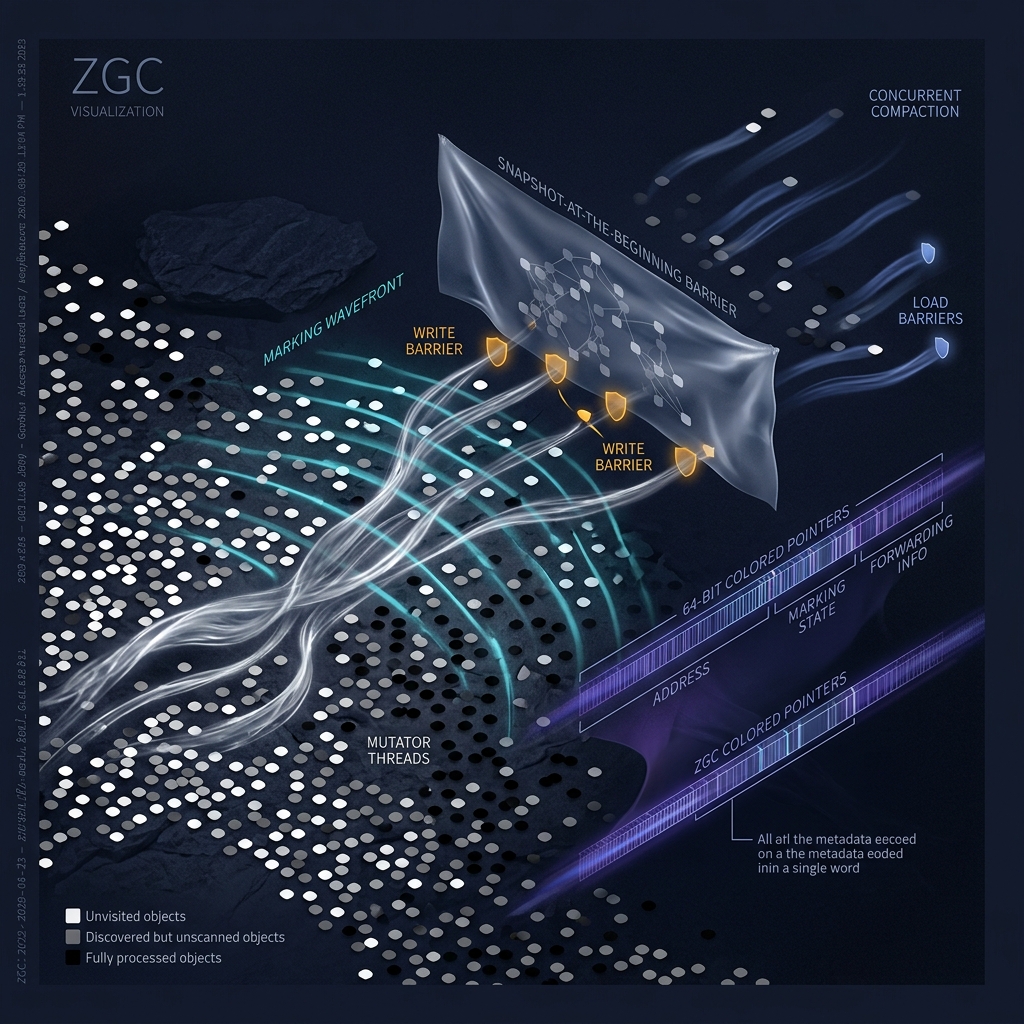
Write barriers: The mutator notifies the collector whenever it modifies a pointer field. The write barrier can be “snapshot-at-the-beginning” (SATB) — preserving the object graph as it existed at the start of marking — or “incremental update” — ensuring that new references from black objects to white objects are handled by re-coloring the white object gray.
Read barriers: The mutator notifies the collector whenever it reads a pointer from the heap. The read barrier can ensure that the mutator never sees pointers to white objects (the collector traps the read and colors the object gray) or never sees stale pointers to moved objects (the collector updates the pointer on read).
3. Snapshot-at-the-Beginning (SATB)
The SATB barrier, pioneered by Yuasa in 1990 and adopted by G1 (Garbage-First) and Shenandoah, takes a conservative approach: preserve the object graph as it existed at the moment marking began. Every pointer that was reachable at the start of marking is considered live, even if the mutator later overwrites it.
The SATB write barrier works as follows: whenever the mutator stores a reference into a field of a heap object, the barrier records the old value (the reference that was in the field before the store) in a “SATB buffer.” The old value is logged because it represents an edge that was present at the start of marking. If that edge was removed by the mutator’s store, the collector still needs to follow it to ensure reachability.
When the SATB buffer fills up, the collector processes it, marking all logged references and their reachable objects. This is a form of “concurrent marking” — the collector runs concurrently with the mutator, processing SATB buffers and tracing the object graph. The mutator and collector communicate through the write barrier and the SATB buffers.
The SATB approach has two important properties:
Precision: All objects that are live at the start of marking will be retained, even if they become unreachable during marking. This means some floating garbage (objects that became unreachable after marking started) will survive one collection cycle and be collected in the next.
Snapshot consistency: The marking phase sees a consistent snapshot of the heap. This makes concurrent compaction (moving objects while the mutator runs) simpler because the collector knows exactly which references need to be updated.
Shenandoah uses SATB for its concurrent marking phase. When marking completes, Shenandoah enters a concurrent evacuation phase where it copies live objects to new locations and updates all references using a Brooks-style forwarding pointer (each object has a “forwarding pointer” that is atomically updated to point to the new location).
4. ZGC and Colored Pointers
ZGC, introduced by Oracle in JDK 11 (2018), takes a fundamentally different approach to concurrent compaction: it embeds metadata directly into object pointers using a technique called “colored pointers.” On a 64-bit system, pointers are typically 48-bit virtual addresses (bits 0-47), leaving 16 bits (48-63) available for metadata. ZGC uses several of these bits to encode the object’s state:
Marked bits: Indicate whether the object has been marked during the current collection cycle.
Remapped bits: Indicate whether the pointer has been updated to point to the object’s new location after compaction.
Finalizable bit: Indicates whether the object has a finalizer (a
finalize()method that must be called before the object is collected).
When ZGC compacts the heap (moves objects to new locations), it installs a “forwarding table” (not forwarding pointers in each object, but a separate data structure) that maps old addresses to new addresses. The remapped bit in the pointer tells the mutator whether the pointer has already been updated. If the mutator accesses an object through a non-remapped pointer, a read barrier intercepts the access, looks up the new address in the forwarding table, updates the pointer (atomically), and sets the remapped bit. Subsequent accesses through the same pointer skip the barrier because the remapped bit is set.
The colored pointer approach has several advantages:
No object header changes: Unlike Shenandoah’s Brooks-style forwarding pointers, ZGC doesn’t modify object headers to store forwarding information. This simplifies the implementation and avoids cache line contention on the forwarding pointer.
Fine-grained state tracking: Each pointer can independently track whether it has been remapped, which means multiple threads accessing the same object through different pointers don’t contend on a shared forwarding pointer.
Fast rematerialization: When a pointer is loaded from the heap during marking, ZGC can check the marked and remapped bits to determine whether the object is already marked, needs to be marked, or has been moved.
The cost is that colored pointers are not standard pointers — the JIT must emit special instructions to check and update the metadata bits. On x86-64, this requires a few additional instructions per pointer access. ZGC’s performance overhead is typically 5-10% compared to G1 (which doesn’t use colored pointers), but the pause times are dramatically lower: ZGC targets sub-millisecond pauses regardless of heap size, while G1 targets sub-100-millisecond pauses.
5. Load Barriers and the Mutator-Collector Interface
Concurrent collectors communicate with the mutator through barriers — small snippets of code inserted by the JIT at every pointer load and/or store. The choice between load barriers and store barriers (or both) has profound implications for performance and complexity.
Store barriers (used by G1, CMS) execute when the mutator writes a pointer to the heap. They are “write-triggered.” The SATB barrier described above is a store barrier. Store barriers are relatively cheap because stores are less frequent than loads (in typical Java code, loads outnumber stores by 3:1 to 5:1). However, store barriers alone cannot enable concurrent compaction — if the collector moves an object, the mutator needs a way to find the new location, which requires a load barrier.
Load barriers (used by ZGC, Shenandoah, Azul C4) execute when the mutator reads a pointer from the heap. They are “read-triggered.” Load barriers are more expensive than store barriers because loads are more frequent. However, load barriers enable “self-healing” — the barrier can update the pointer to point to the new object location, so subsequent loads through the same pointer skip the barrier. This makes concurrent compaction possible.
Azul C4 (Continuously Concurrent Compacting Collector) used a hardware load barrier on Azul’s custom Vega processor. The Vega instruction set included a “load reference with barrier” (LRB) instruction that checked whether the loaded reference pointed to an object that had been moved, and if so, updated the reference atomically. The hardware barrier was essentially free (it added no cycles to the load), which made C4’s concurrent compaction exceptionally efficient.
On commodity hardware, load barriers must be implemented in software. ZGC’s load barrier (the “colored pointer” check) adds 2-4 instructions per pointer load. Shenandoah’s load barrier (the Brooks forwarding pointer check) adds 1-2 instructions but requires an extra indirection when the object has been moved. Both are fast enough for production use — the overhead is measured in single-digit percentages for most workloads.
6. Concurrent Compaction: Moving Objects Without Stopping the World
Compacting garbage collection — moving live objects together to eliminate fragmentation — is critical for large heaps. Without compaction, a long-running server with a 100 GB heap would fragment into unusably small free blocks, eventually causing allocation failures even though plenty of total free space exists. But compaction is hard to do concurrently because moving an object requires updating every pointer that points to it, and those pointers could be in registers, on stacks, or in heap objects that are being concurrently accessed by other threads.
Concurrent compaction algorithms solve this through a multi-phase approach:
Phase 1 — Mark: Identify all live objects (concurrent with mutator).
Phase 2 — Relocate: Determine where each live object will be moved to. Install forwarding information (either in the object header, in a separate forwarding table, or in colored pointer metadata).
Phase 3 — Remap: Update all pointers that point to relocated objects (concurrent with mutator). This is the hardest phase because it requires finding and updating every reference to every moved object.
Phase 4 — Reclaim: Free the old memory regions (now empty because all live objects have been moved).
Shenandoah’s concurrent compaction uses a Brooks-style forwarding pointer: each object header contains a pointer that normally points to itself (indicating “not forwarded”) and is atomically updated to point to the new location when the object is moved. When the mutator loads a reference to a forwarded object, the load barrier follows the forwarding pointer and returns the new address. The mutator also has the option to update its local reference (CAS the forwarding pointer into the original location), which self-heals — subsequent loads don’t need the barrier because the reference now points directly to the new location.
ZGC’s concurrent compaction, as described above, uses a global forwarding table indexed by the original page address. The remap phase walks all thread stacks, all registers, and all heap objects, updating pointers that contain non-remapped color bits. Because this is a massive amount of work, ZGC parallelizes it aggressively across all available threads.
7. Pauseless Collectors: The State of the Art
A truly pauseless collector never stops all mutator threads simultaneously. There is always at least one thread running application code. Achieving this requires not just concurrent marking and concurrent compaction, but also concurrent root scanning (scanning thread stacks without stopping threads) and concurrent reference processing (handling weak, soft, and phantom references without stopping).
Azul C4 was the first pauseless collector. On Azul’s custom Vega hardware, C4 used the hardware read barrier to enable fully concurrent compaction. Thread stacks were scanned using a cooperative protocol: each thread periodically checked a flag indicating that stack scanning was needed and voluntarily reported its stack roots to the collector. This was genuinely pauseless — no thread was ever forced to stop.
ZGC and Shenandoah are “pause-time” collectors, not truly pauseless. They still have short stop-the-world phases for root scanning (scanning thread stacks) and for certain synchronization points. However, their pause times are independent of heap size — ZGC targets sub-millisecond pauses, and Shenandoah targets sub-10-millisecond pauses, regardless of whether the heap is 1 GB or 1 TB. This is a transformative improvement over traditional collectors where pause time scales linearly (or worse) with heap size.
The remaining stop-the-world phases in ZGC are:
Thread-local handshakes: Each thread is briefly paused (not all threads simultaneously, but in rapid succession) to scan its stack roots. This takes microseconds per thread.
Synchronization points: Between phases, all threads must acknowledge the phase transition. This takes microseconds on modern hardware because it’s essentially a global barrier with no actual work.
ZGC’s pause time target of sub-millisecond is achieved. On a 16 TB heap (the theoretical maximum for ZGC), a full collection cycle completes with less than 1 millisecond of cumulative stop-the-world pause time. The concurrent phases — marking, relocation, remapping — run in the background across multiple threads, invisible to the application.
16. GC and Memory Ordering: The Hardware-Software Interface
Concurrent garbage collectors interact with the CPU’s memory model at a deep level. The write barrier that records modifications to the object graph must be correctly ordered with respect to the mutator’s stores and the collector’s loads. On weakly-ordered architectures (ARM, RISC-V), this requires explicit memory barrier instructions (dmb, fence) to ensure that the collector sees stores in the correct order.
Consider the SATB write barrier: the mutator stores a new value to a field, and the barrier logs the old value. The barrier must ensure that the old value is read before the new value is visible to the collector. On x86 (which has total store order), this ordering is guaranteed by the hardware — stores become visible in program order. On ARM, the barrier must include a dmb ishst (data memory barrier, inner shareable, store-store) to prevent the new store from becoming visible before the old value is logged. Getting this ordering wrong results in the “lost object problem” — the collector misses a live object and incorrectly reclaims it.
The memory ordering requirements for load barriers (ZGC, Shenandoah) are even more stringent. When the mutator loads a reference to a forwarded object, the load barrier must follow the forwarding pointer and return the new address. This requires a “load-load” ordering: the load of the forwarding pointer must see the value that the collector stored (when it moved the object), not a stale value from the mutator’s local cache. On ARM, this requires a dmb ishld (load-load barrier) before accessing the forwarded object’s fields. These barriers add latency to every object access, which is why concurrent compaction has higher overhead than stop-the-world compaction.
17. Summary
The journey from stop-the-world collection to pauseless collection spans four decades of algorithmic innovation. The key breakthroughs — the tricolor abstraction (Dijkstra, 1978), write barriers for concurrent marking (Yuasa, 1990), hardware load barriers for concurrent compaction (Azul, 2005), and colored pointers for concurrent compaction on commodity hardware (ZGC, 2018) — have progressively decoupled collection pause time from heap size.
Modern concurrent collectors — G1, Shenandoah, ZGC — bring sub-millisecond pause times to commodity servers, making Java viable for latency-sensitive applications that once required manual memory management in C or C++. The cost is a modest throughput overhead (5-15%) compared to stop-the-world collectors, which is an easy trade for most applications where predictable latency matters more than peak throughput. The colored pointer technique pioneered by ZGC is particularly elegant: by embedding collection state in the pointer itself, ZGC eliminates the need for object header mutations during compaction, reducing cache coherence traffic. As 64-bit address spaces remain generously larger than physical memory, the “wasted” bits are a resource that clever collector designers can exploit. The future of garbage collection is bright — and it doesn’t stop the world.
8. Summary
The journey from stop-the-world collection to pauseless collection spans four decades of algorithmic innovation. The key breakthroughs — the tricolor abstraction (Dijkstra, 1978), write barriers for concurrent marking (Yuasa, 1990), hardware load barriers for concurrent compaction (Azul, 2005), and colored pointers for concurrent compaction on commodity hardware (ZGC, 2018) — have progressively decoupled collection pause time from heap size.
Modern concurrent collectors — G1, Shenandoah, ZGC — bring sub-millisecond pause times to commodity servers, making Java (and other managed languages) viable for latency-sensitive applications that once required manual memory management in C or C++. The cost is a modest throughput overhead (5-15%) compared to stop-the-world collectors, which is an easy trade for most applications where predictable latency matters more than peak throughput.
The colored pointer technique pioneered by ZGC is particularly elegant: by embedding collection state in the pointer itself, ZGC eliminates the need for object header mutations during compaction, reducing cache coherence traffic and enabling fine-grained, per-pointer state tracking. As 64-bit address spaces remain generously larger than physical memory, the “wasted” bits are actually a resource that clever collector designers can exploit. The future of garbage collection is bright — and it doesn’t stop the world.
9. The G1 Garbage Collector: Regional Collection
The Garbage-First (G1) collector, introduced in Java 7 and made the default in Java 9, represents a middle ground between stop-the-world collectors and fully concurrent ones. G1 divides the heap into equal-sized “regions” (typically 1-4 MB each) and collects garbage region-by-region rather than across the entire heap. This enables G1 to target a specific pause time goal (set via -XX:MaxGCPauseMillis) and collect only as many regions as needed to meet that goal, leaving the rest for later collections.
G1’s collection cycle begins with a concurrent marking phase that identifies live objects across the entire heap, using a SATB (Snapshot-At-The-Beginning) write barrier to maintain marking consistency while the application runs. After marking completes, G1 selects a set of regions with the most garbage (the “garbage-first” regions) for evacuation — copying live objects out of those regions into fresh regions, then reclaiming the evacuated regions. The evacuation is a stop-the-world phase, but it typically processes only a fraction of the heap (the high-garbage regions), so pause times are bounded.
G1 also supports “mixed collections” that combine young-generation collection (collecting the eden and survivor spaces) with old-generation collection (evacuating some high-garbage old regions). The young generation is collected in every GC cycle; old-generation regions are collected incrementally, spread across multiple cycles to stay within the pause time target. This incremental approach to old-generation collection is what makes G1’s pause times predictable: the work per cycle is proportional to the number of regions being evacuated, not the total heap size.
10. The GC Future: Generational ZGC and Beyond
The next frontier for concurrent collectors is generational collection. Both ZGC and Shenandoah currently treat all objects uniformly, collecting the entire heap in every cycle. This works because their concurrent phases overlap with application execution, but it means they process many long-lived objects that don’t need to be collected. Generational ZGC (in development for JDK 21+) will add a young generation that is collected more frequently, reducing the amount of work per collection cycle and improving throughput for allocation-heavy workloads. The challenge is doing generational collection concurrently — moving young objects without stop-the-world pauses requires careful coordination between the young-generation collector and the concurrent old-generation collector.
Beyond generational collection, researchers are exploring region-based GC that integrates with the programming language’s type system to determine object lifetimes at compile time (recalling the region calculus of Tofte and Talpin), hardware-accelerated GC that uses memory protection hardware (MMU/IOMMU) for read/write barriers, and fully deterministic GC for real-time systems where even sub-millisecond pauses are unacceptable. The journey from Dijkstra’s tricolor abstraction in 1978 to ZGC’s colored pointers in 2018 took forty years. The next forty years will bring collectors we can barely imagine today.
11. Shenandoah: Concurrent Compaction with Brooks Pointers
Shenandoah, developed by Red Hat and included in OpenJDK since JDK 12, takes a different approach to concurrent compaction than ZGC. Instead of colored pointers with a global forwarding table, Shenandoah uses Brooks-style forwarding pointers: each object header contains a pointer that normally points to itself, and when the object is moved, this pointer is atomically updated to point to the new location.
The Brooks forwarding pointer enables a remarkably simple concurrent compaction algorithm. When the GC decides to move an object, it atomically CASes the forwarding pointer from self-reference to the new location. Any thread that subsequently accesses the object (through any reference) will see the forwarding pointer and follow it to the new location. The load barrier is just one extra indirection: check if the object’s forwarding pointer points to itself; if so, use the original reference; if not, follow the forwarding pointer.
Shenandoah’s concurrent compaction proceeds in phases: concurrent marking (SATB-based), concurrent evacuation (copy live objects from selected regions), concurrent update-references (walk the heap and update all pointers to evacuated objects), and concurrent cleanup (reclaim evacuated regions). All phases run concurrently with the application. The only stop-the-world pauses are for root scanning (scanning thread stacks) and for thread-local handshakes at phase transitions, both of which are independent of heap size.
The Brooks pointer approach has a subtle trade-off: every object access pays the cost of the forwarding pointer check (one extra load+compare), but there is no global forwarding table to maintain. For workloads with high object mutation rates, Shenandoah can be faster than ZGC because the forwarding information is colocated with the object (no extra cache miss for the forwarding table). For workloads with many pointer loads and few mutations, ZGC’s colored pointer approach can be faster because the load barrier validates the pointer without accessing the object’s header.
12. Practical GC Tuning for Production Workloads
Choosing and tuning a garbage collector for production is both art and science. The key parameters are heap size, allocation rate, live set size, and latency tolerance. For batch processing (no latency requirements), a parallel stop-the-world collector (-XX:+UseParallelGC) maximizes throughput by using all available CPUs for GC. For interactive applications (web servers, user-facing services), G1 is the default and usually the right choice, with -XX:MaxGCPauseMillis=100 as a starting point. For latency-critical applications (trading systems, real-time analytics), ZGC or Shenandoah with sub-millisecond pause targets are the only viable options, at the cost of 5-15% throughput overhead.
Monitoring GC behavior is essential. The -Xlog:gc* flag enables detailed GC logging, including pause times, heap occupancy, and promotion rates. Tools like JFR (Java Flight Recorder), GCeasy, and GCViewer provide visualization and analysis of GC logs. Key metrics to watch: GC pause time percent (should be <1% for most applications), GC throughput (should be >99%), and allocation rate (should be stable; sudden increases indicate a memory leak or workload change).
13. GC Performance Instrumentation and Analysis
Understanding GC behavior in production requires sophisticated tooling. Java Flight Recorder (JFR) provides low-overhead GC event logging that captures every GC cycle: the start and end times, the heap occupancy before and after, the pause times, the promotion rates, and the reference processing times. JFR’s overhead is typically less than 1%, making it suitable for always-on production profiling. The resulting recordings can be analyzed with JDK Mission Control (JMC) or converted to JSON for integration with monitoring systems.
Key GC metrics to monitor in production: allocation rate (bytes allocated per second — should be stable; a monotonic increase indicates a memory leak), promotion rate (bytes promoted from young to old generation per second — should be less than the old generation collection rate; otherwise, the old generation fills up), GC pause time percent (percentage of wall-clock time spent in GC pauses — should be <1% for most applications), and heap occupancy after collection (should return to a stable baseline after each full GC; if it creeps up, there’s a leak).
Tools like GCeasy and GCEasy.io provide automated analysis of GC logs, identifying issues like: “Humongous allocations causing fragmentation” (objects larger than half a G1 region are allocated as humongous objects, which can fragment the heap), “GC overhead limit exceeded” (the JVM spends more than 98% of CPU time in GC and recovers less than 2% of the heap, indicating severe memory pressure), and “Allocation stalls” (application threads are blocked waiting for GC to free memory). These tools have codified the expertise of GC tuning into automated diagnostics.
14. GC Myths and Misconceptions
Several persistent myths about garbage collection deserve clarification. “GC is always slower than manual memory management” — false. Generational GC can be faster than malloc/free for allocation-intensive workloads because bump-pointer allocation in the young generation is faster than a general-purpose malloc (which must search free lists). GC overhead is in collection, not allocation. “GC pause times are uncontrollable” — false for modern concurrent collectors. ZGC and Shenandoah have pause times independent of heap size and live set size, bounded by root scanning time (number of threads, not amount of data). “You should always use the latest GC” — false. G1 is the right choice for most server applications (predictable sub-100ms pauses, good throughput). ZGC and Shenandoah are for latency-critical applications that can tolerate 5-15% throughput reduction. The parallel collector (-XX:+UseParallelGC) is still the best for batch processing where throughput matters more than latency.
Another common misconception is that GC eliminates memory leaks. GC eliminates certain classes of leaks (unreachable objects are always collected), but it doesn’t eliminate unintentional object retention — holding references to objects that are no longer logically needed. A HashMap that grows without bound as new keys are added (but old keys are never removed) is a memory leak, even with GC. Profiling tools (JFR, heap dumps) can identify these “logical leaks” by showing which objects are consuming memory and what references are keeping them alive.
15. GC in Non-Java Environments: .NET, Go, and Python
While Java’s GC landscape is the most studied, other managed runtimes have evolved their own approaches. .NET’s GC is a generational, concurrent workstation/server collector with two modes: workstation (low latency for UI applications) and server (high throughput for web servers). .NET 7 introduced “regions” (similar to G1’s regions) for the server GC, replacing the previous segment-based heap. .NET’s GC is tightly integrated with the CLR’s type system and can take advantage of value types (structs allocated inline, not on the heap) to reduce GC pressure.
Go’s GC is a concurrent, non-generational, non-compacting mark-sweep collector. It’s designed for low latency (targeting sub-millisecond pauses) at the cost of higher memory usage (no compaction means potential fragmentation). Go’s GC is non-generational because Go allocates many objects on the stack (via escape analysis), reducing the benefit of a young generation. Go’s GC is also “ballast” friendly: allocating a large ballast of memory early in the process lifetime and freeing it after GC stabilizes can reduce GC frequency.
Python’s CPython uses reference counting as the primary GC mechanism, supplemented by a generational cyclic garbage collector (which collects reference cycles that refcounting alone can’t handle). Reference counting provides deterministic finalization (an object is freed immediately when its reference count drops to zero) but has overhead (every reference assignment requires incrementing/decrementing a counter). PyPy uses a generational, moving GC (similar to HotSpot’s parallel collector) and achieves significantly better GC performance than CPython for allocation-heavy workloads.
18. The NUMA-Aware Collector: Memory Topology Meets GC
Modern multi-socket servers have non-uniform memory access (NUMA): each CPU socket has its own local memory controller, and accessing remote memory (memory attached to another socket) is 1.5-2x slower than accessing local memory. Garbage collectors that are unaware of NUMA topology can suffer significant performance degradation because objects may be allocated on one socket and accessed by threads running on another socket.
ZGC includes NUMA-aware allocation: when a thread allocates an object, ZGC preferentially allocates it from the local NUMA node’s memory pool. Small pages (2 MB) are grouped by NUMA node, and the allocator selects pages from the local node when possible. During relocation (compaction), ZGC tries to keep objects on the same NUMA node, minimizing remote memory accesses. This NUMA awareness is automatic — the application doesn’t need to be modified — and it can improve performance by 20-40% on multi-socket systems for memory-intensive workloads.
Shenandoah also supports NUMA-aware heuristics: during evacuation, objects are preferentially moved to regions on the same NUMA node. The SATB write barrier records references that cross NUMA boundaries, allowing the collector to identify objects that are “stranded” on the wrong node (allocated on socket 0 but accessed by threads on socket 1) and move them to the correct node during the next GC cycle. This adaptive NUMA balancing is an example of how modern GCs go beyond “just collecting garbage” to actively optimizing memory layout for hardware topology.