Timeouts, Retries, and Idempotency Keys: A Practical Guide
Make your distributed calls safe under partial failure. How to budget timeouts, avoid retry storms, and use idempotency keys without shooting yourself in the foot.
Every distributed call needs three decisions: how long to wait, how to retry, and how to avoid duplicate effects. Done right, these three give you calm dashboards during partial failures; done wrong, they turn blips into incidents. This is a practical guide you can wire into client libraries and services without heroics.
Budget your time, not per‑hop timeouts
Propagate a request deadline. Each hop consumes a slice and passes the remainder. Treat it as a budget: if it’s nearly spent, fail fast. Per‑hop fixed timeouts accumulate and blow your SLOs because each layer waits its entire local timeout.
Use absolute deadlines, not relative timeouts. Carry them in headers/metadata; compute remaining budget = deadline − now at each hop and set local timeouts to a fraction of the remainder with a small safety margin. If the budget is gone, fail fast with a retriable error and a reason indicating budget exhaustion.
Implementation notes:
- Synchronize clocks (NTP/Chrony).
- Choose sane defaults per class: e.g., 200–500 ms reads, 1–3 s writes.
- Enforce a floor and ceiling for local timeouts to avoid degenerate zero or hour‑long waits.
Retry sanely
Retries should be selective and bounded by budgets. A simple but effective policy matrix:
- Retry on transient transport errors (TCP resets), 502/503, connection refused, and timeouts, with exponential backoff + full jitter.
- Respect Retry‑After and server backoff hints.
- Don’t retry validation (4xx) or permanent errors.
- For 409 conflict, retry with application logic if safe.
Backoff parameters: start ~50–100 ms, multiplier 2×, cap at 1–2 s. Always check the remaining budget before each attempt and stop when there’s not enough left to plausibly succeed.
Guard against retry storms: cap concurrent in‑flight attempts per client and add token buckets so you don’t slam recovering services.
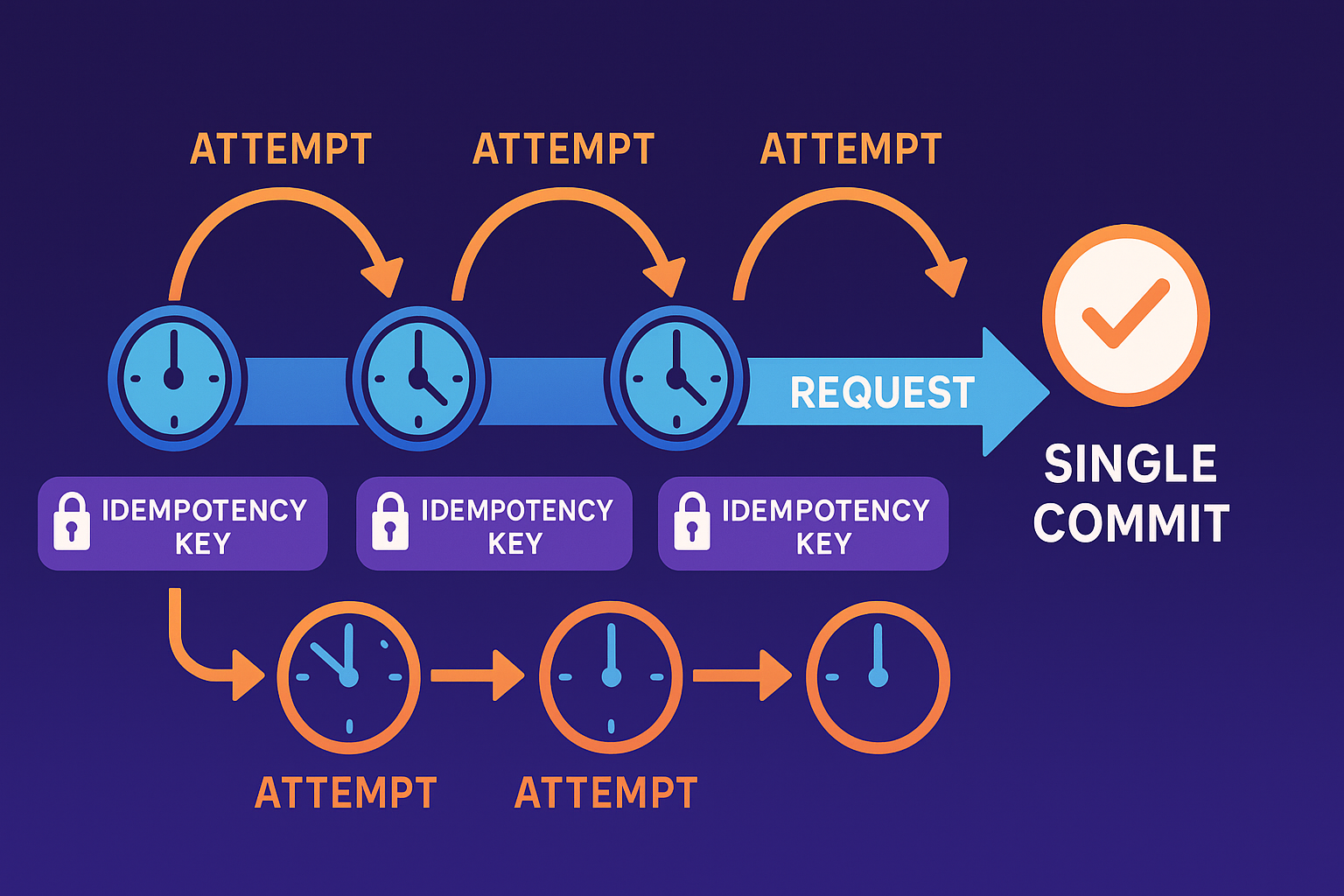
Idempotency keys
Attach a unique key to an operation so retries don’t duplicate side effects. The server stores a tiny record keyed by that idempotency key with outcome and expiry. On duplicates, it either coalesces with an in‑flight attempt or returns the stored result.
Pitfalls and patterns:
- Scope keys correctly (tenant, operation, resource).
- Store a hash of the payload; if a duplicate key arrives with different payload, reject with 409.
- GC keys conservatively; keep them long enough to cover delayed retries.
- Prefer naturally idempotent operations (PUT/UPSERT), and wrap non‑idempotent ones (payments) behind keys and unique transaction IDs in the ledger.
Observability
Emit metrics on deadline usage, retry counts, and deduplications. Sample request traces with annotations on retry decisions. Alert on budget‑depletion patterns and spikes in attempts per request.
1) Deadlines vs timeouts: wiring budgets end‑to‑end
Deadlines are absolute timestamps that travel with the request. Each service computes remaining budget and sets local timeouts accordingly. This prevents the “sum of timeouts > SLO” trap.
How to implement:
- Define a standard header (e.g., X‑Deadline or use grpc‑timeout).
- Middleware/interceptors read the deadline, compute remaining budget, and set local timeouts.
- If the deadline is missing, apply a sane default per endpoint.
- On expiry, return a retriable error and tag spans with deadline_exhausted=true.
Edge cases: clock skew, cross‑region calls, and batch operations with a single deadline. When skew is significant, prefer relative budgets communicated as durations and compute absolute deadlines locally.
2) Choosing retry policies by error class
Separate errors into three buckets: retryable, do‑not‑retry, and reconcile‑then‑retry.
- Retryable: transient network failures, 5xx, timeouts. Use exponential backoff + full jitter and honor Retry‑After.
- Do‑not‑retry: 4xx that indicate caller bugs (400/401/403/404/422).
- Reconcile‑then‑retry: 409 conflicts, optimistic lock failures, and idempotent‑but‑ambiguous operations.
Prefer bounded retries: e.g., 3 attempts or until budget < base backoff, whichever comes first. For streaming or long‑poll operations, use resumable tokens instead of plain retries.
3) Designing idempotency that actually dedupes
An idempotency key system consists of:
- A key: opaque client token with scope (tenant, operation, resource).
- A store: fast KV for (key → status, payload hash, result pointer, expiry).
- A protocol: first request writes an in‑flight marker; duplicates attach to the same work or return the stored result.
Key store options: Redis (with AOF/RDB persistence), DynamoDB/Spanner with conditional puts, or a SQL table with primary key on key. Ensure write‑path durability; a crash after committing side effects but before recording completion must still let duplicates return the original result—store a durable pointer to the system of record.
Retention: set TTL based on maximum expected retry window (hours to days). For very high volume, compact results and store only hashes + pointers.
4) Exactly‑once is marketing; effectively‑once is engineering
You can’t guarantee exactly‑once across unreliable networks without consensus and transactions everywhere. Instead, guarantee that repeated application of the same operation key leads to the same state (“idempotent” or “effectively‑once”). Make this explicit in APIs and docs. For payments, use unique charge IDs; for job submission, dedupe by client‑generated job ID.
5) Coordinating across services and queues
In microservice chains, propagate the idempotency context. If service A creates an order and then calls payment B, either reuse the same key or derive a new one deterministically (HMAC(parent_key, “payment”)). Message queues should carry the key in headers; consumers dedupe.
For at‑least‑once streams (Kafka, SQS), store processed offsets or use transactional consumers (Kafka’s idempotent producers and transactions) to avoid duplicates downstream. If duplicates happen, idempotency keys at sinks prevent double effects.
6) Client libraries: put the good behavior in one place
Centralize policy in clients so every team benefits:
- Implement a retry matrix keyed by protocol status codes.
- Add jitter, budgets, and concurrency caps.
- Provide helpers for idempotency keys (generation, scoping, hashing).
- Surface hooks for observability and per‑endpoint overrides.
7) Storage, capacity, and cost of key stores
Plan for growth: keys/sec × retention = live records. Apply TTLs and periodic sweeps. Partition by tenant to keep hotspots isolated. For extremely high throughput, shard the key space and cache recent keys in memory with a write‑through policy to the durable store.
8) Pitfalls from the field
- Retry amplification: many clients retry at once; server collapses. Fix with jitter, budgets, and server‑side overload protection (queue caps, 503 + Retry‑After).
- Key misuse: clients reuse keys across operations; payload hashing catches it early.
- Region drift: keys written in region A not visible in B; either make writes regional and route requests accordingly or use a globally replicated store.
- Partial commits: client times out but server succeeds; idempotency resolves ambiguity by returning the same result on retry.
9) Testing and chaos
- Fault injection: drop, delay, and duplicate requests. Validate that keys dedupe and retries settle.
- Skew tests: misconfigure time on a canary to surface deadline issues.
- Property tests: assert repeated application with the same key is stable.
- Load tests: monitor retry rates under overload; ensure budgets prevent runaway attempts.
10) Observability that drives action
Track attempts per request, deadline exhaustion rate, dedup hit ratio, and key store latency/error rates. Correlate spikes in retries with upstream/downstream incidents. Build runbooks: “when Retry‑After ignored > X%, push client config update.”
11) Reference blueprint
- Ingress sets deadlines and enforces max.
- Client library retries with jitter, bounded by deadline.
- Servers require idempotency keys for state‑changing calls; store (key, payload_hash, status, result_ref, expiry).
- Duplicate handling: coalesce in‑flight; on completion return stored result; on mismatch 409.
- Daily sweeper prunes expired keys; dashboards show dedup hits and expirations.
12) API sketches
HTTP example: POST /payments with Idempotency‑Key: payment:create:tenant123:order456. The service conditionally inserts the key (if absent → proceed; if present → compare payload hash). On retry, it returns the original outcome without re‑charging. gRPC carries deadlines and keys in metadata; interceptors enforce budgets and retry policies.
13) Checklists you can paste into PRs
- Deadlines propagated and enforced end‑to‑end
- Retry matrix with jitter, caps, and budgets
- Idempotency keys scoped, stored with TTL, and payload‑hashed
- Concurrent duplicate coalescing
- Observability: attempts, dedup hits, budgets, key store health
- Runbooks for overload and key store outages
14) When not to retry
For non‑reentrant third‑party side effects (e.g., sending SMS via flaky providers), prefer transactional outboxes and reconciliation over blind retries. For ultra‑low‑latency paths, a single try with a tight deadline may beat any backoff logic.
Reliability emerges from budgeted timeouts, principled retries, and idempotency as a contract. Bake these into your defaults so that correctness is the easy path—and noisy nights become rare.
15) Budgets by numbers: back‑of‑the‑envelope math
Suppose your user‑visible SLO for a read is 200 ms. You have API Gateway, Service A, Service B, and a database hop. A naive split gives 50 ms per hop, but that ignores variance. A better approach is budget by percentiles and class:
- Gateway: 10–20 ms (mostly routing).
- Service A: 60–80 ms (business logic + cache).
- Service B: 40–60 ms.
- DB: 40–60 ms.
- Slack: 20–30 ms.
If A calls B, A should pass the remaining budget to B. A’s local timeout might be min(remaining − 20 ms, 80 ms), ensuring that a slow B doesn’t exhaust the whole 200 ms. Your retry strategy for B must then be base 25 ms, 2× backoff, cap 60 ms, but stop when remaining < 30 ms. This guarantees at most two attempts in practice without stealing from the user’s total experience.
16) Coordinating overload between client and server
When a service is overloaded, the worst thing clients can do is keep retrying aggressively. Build a handshake:
- Servers advertise overload with 429/503 and Retry‑After.
- Clients honor Retry‑After and scale back concurrency (token bucket shrink).
- Both sides log correlation IDs so you can prove clients behaved during incidents.
- If servers observe Retry‑After violations, trigger circuit breakers for offending callers.
Server‑side, apply queue caps and shed work early. Do not enqueue work you cannot finish; it only consumes memory and bloats tails.
17) Outbox/inbox and sagas: idempotence across boundaries
Side effects to external systems benefit from the outbox pattern: write the business change and an “outbox” record in the same transaction; a reliable relay publishes the outbox to a message bus. Downstream services maintain an “inbox” table keyed by message ID (or idempotency key) to dedupe processing. This yields at‑least‑once delivery with idempotent handling.
For multi‑step operations (reserve inventory → charge card → confirm order), use sagas: each step is idempotent and has a compensating action. If a later step fails permanently, prior steps are undone via compensations. Idempotency keys ensure compensations aren’t applied twice.
18) Queues and streams: semantics matter
- At‑most‑once delivery: no retries; simplest but loses messages under failure. Idempotency optional.
- At‑least‑once: common; consumers must be idempotent. Use keys to dedupe and store processed offsets.
- Exactly‑once (effectively‑once): achievable within one system (e.g., Kafka transactions) but brittle across multiple systems. Prefer idempotent sinks.
When mixing HTTP and queue consumers, normalize idempotency semantics: carry the same key in both paths; the sink dedupes by key.
19) Payments and money: concrete patterns
Never retry “charge card” without a unique transaction ID persisted in your ledger. The client’s idempotency key maps to this transaction ID. On retry, the payment gateway should return the existing transaction result. If the gateway is not idempotent, build your own shim that dedupes by transaction ID so you never double‑charge.
Refunds and reversals should also be idempotent; use refund IDs bound to the original charge ID.
20) Clock drift and deadlines
Distributed deadlines assume bounded clock skew. Monitor skew actively (NTP, Chrony), expose worst‑case skew in metrics, and subtract it from budgets when in doubt. If you detect skew spikes, prefer relative budgets (duration) converted locally to absolute deadlines.
21) gRPC and HTTP details
- gRPC: use grpc‑timeout metadata; configure per‑method retry policies via service config; add interceptors for idempotency keys and attempt annotations.
- HTTP: choose headers (Idempotency‑Key, X‑Deadline, Retry‑After); document semantics clearly. For REST, prefer PUT/DELETE with resource IDs for natural idempotence; for POST, require keys on state‑changing endpoints.
22) Case studies from the trenches
- Incident 1: gateway blip returned 502 for 30 seconds; naive clients retried instantly with no jitter, multiplying load by 5× and extending the incident. After adding jitter and honoring Retry‑After, the same blip recovered in under 10 seconds with flat tails.
- Incident 2: idempotency key store outage caused duplicate payments; fix was a dual‑write design with a durable ledger keyed by transaction ID and a local cache with write‑through behavior.
- Incident 3: cascading timeouts from a slow database; budgets prevented upper layers from waiting uselessly, and tail latency alerts routed SREs to the DB first.
23) Tuning guide by symptom
- Too many attempts per request: reduce base backoff, raise jitter, and lower concurrency caps.
- Budget exhaustion frequent on first hop: increase initial deadlines or optimize that hop; don’t steal budget from downstream if the first hop is dominant.
- Key collisions: namespace keys with tenant and operation; enforce payload hashing.
- Key store hot partition: shard keyspace and use consistent hashing; add a read‑through cache for recent keys.
24) Security: don’t create replay vectors
Idempotency keys must not allow cross‑tenant replay. Include tenant in the key scope and require auth per request. Keys should be unguessable if they carry meaning; otherwise treat them as opaque tokens tied to authenticated identity.
25) Runbooks you can trust at 3 a.m
Overload:
- Check Retry‑After respect rate; push config to clients if low.
- Enable server‑side shedding and tighten queue caps.
- Reduce background work; reassign capacity to foreground.
- Verify database health to avoid queuing work that will time out.
Idempotency store degraded:
- Switch to degraded mode returning 202 Accepted with a tracking ID; process asynchronously.
- Increase key TTLs; pause GC.
- Monitor duplicate‑effect rate; if rising, disable non‑critical writes.
Deadline exhaustion spike:
- Identify where budget is consumed via trace spans.
- If ingress is too tight, raise default deadline; otherwise optimize hotspots.
- Confirm clock skew metrics; if high, switch to relative duration budgets temporarily.
26) A migration plan
- Introduce deadlines in a non‑enforcing mode; log remaining budgets.
- Roll out client retry libraries with jitter and caps; dark‑launch idempotency key headers.
- Turn on server‑side idempotency storage for a single endpoint; measure dedup hits and latency.
- Expand to all state‑changing endpoints; add dashboards and alerts.
- Teach platform tooling to auto‑generate keys for SDKs where safe.
27) Final checklist
- End‑to‑end deadlines, enforced
- Retry matrix with jitter and budgets
- Idempotency keys with scope, TTL, payload hashing
- Outbox/inbox for external side effects
- Overload handshake (Retry‑After honored)
- Observability tied to runbooks
- Chaos tests for retries and duplicates
28) SDK and platform design
Bake these patterns into your SDKs so product teams don’t reinvent retry wheels:
- Provide a standard client with deadlines, jittered retries, and idempotency helpers turned on by default.
- Ship policy as config (YAML/env) to adjust behavior quickly during incidents without code changes.
- Include a dry‑run mode that logs retry/idempotency decisions without changing behavior—useful for migrations.
- Add middleware hooks so teams can extend metrics/trace annotations uniformly.
29) Mobile and offline considerations
Mobile networks are bursty; devices sleep. Align strategies accordingly:
- Use background sync with exponential backoff and maximum budget per session.
- Persist idempotency keys locally with the request payload to survive app restarts.
- Batch low‑priority writes; for high‑value operations, surface status to users with clear “processing” semantics and eventual confirmation.
- Be conservative with retry limits to avoid battery drain and accidental thundering herds when connectivity returns.
30) Compliance and auditing
Idempotency stores touch regulated domains (payments, PII). Ensure:
- Keys and payload hashes don’t leak sensitive data; hash with a salt and store minimal fields.
- Audit logs record key usage and results for forensics.
- Retention meets legal requirements; implement per‑tenant retention policies.
- Access controls limit who can query the key store and associated results.
31) Example flows end‑to‑end
Payment create:
- Client generates key payment:create:tenant:order123; sends POST with key.
- API validates and upserts into key store with in‑flight status and payload hash.
- Business logic creates ledger entry with unique transaction ID; gateways are called with that ID.
- On success, key store updated with status=success and result_ref=transaction ID.
- Retries return the same result; conflicting payload returns 409.
Job submission:
- Client POSTs job with key job:import:tenant:csvhash.
- Server enqueues idempotently (queue dedup by key); returns job ID.
- Worker processes job; writes results keyed by job ID; idempotency ensures duplicates are no‑ops.
- Client polls with key or job ID; retries don’t re‑enqueue work.
Email send:
- Outbox pattern stores email request with key email:send:tenant:messageID.
- Relay sends via provider with provider‑level idempotency (if supported) or a shim keyed by messageID.
- Retries coalesce; duplicate provider responses are ignored.
32) Wrapping up
Timeouts and retries set the tempo; idempotency keeps you in tune. Wire them once, test them often, and standardize them across teams. The more boring and invisible they become, the more time you’ll have for features—and the fewer incident reviews you’ll attend.
Appendix: quick FAQ addendum
- Do idempotency keys need to be globally unique? No—scope them by tenant and operation to limit blast radius and storage growth.
- What if the idempotency store is eventually consistent? Use conditional writes and prefer stores that guarantee read‑after‑write for keys; otherwise, treat immediate duplicates as in‑flight and poll.
- Can I drop keys after success? Yes, after your maximum retry horizon plus clock skew; for critical flows, keep a compact record longer for auditability.
- Should clients or servers generate keys? Either works; prefer clients for end‑to‑end dedupe and servers as a fallback if clients cannot.
- How do I protect against replay attacks? Authenticate requests, bind keys to identity and operation, and reject cross‑scope replays; expire keys with TTLs.