Tuning CUDA with the GPU Memory Hierarchy
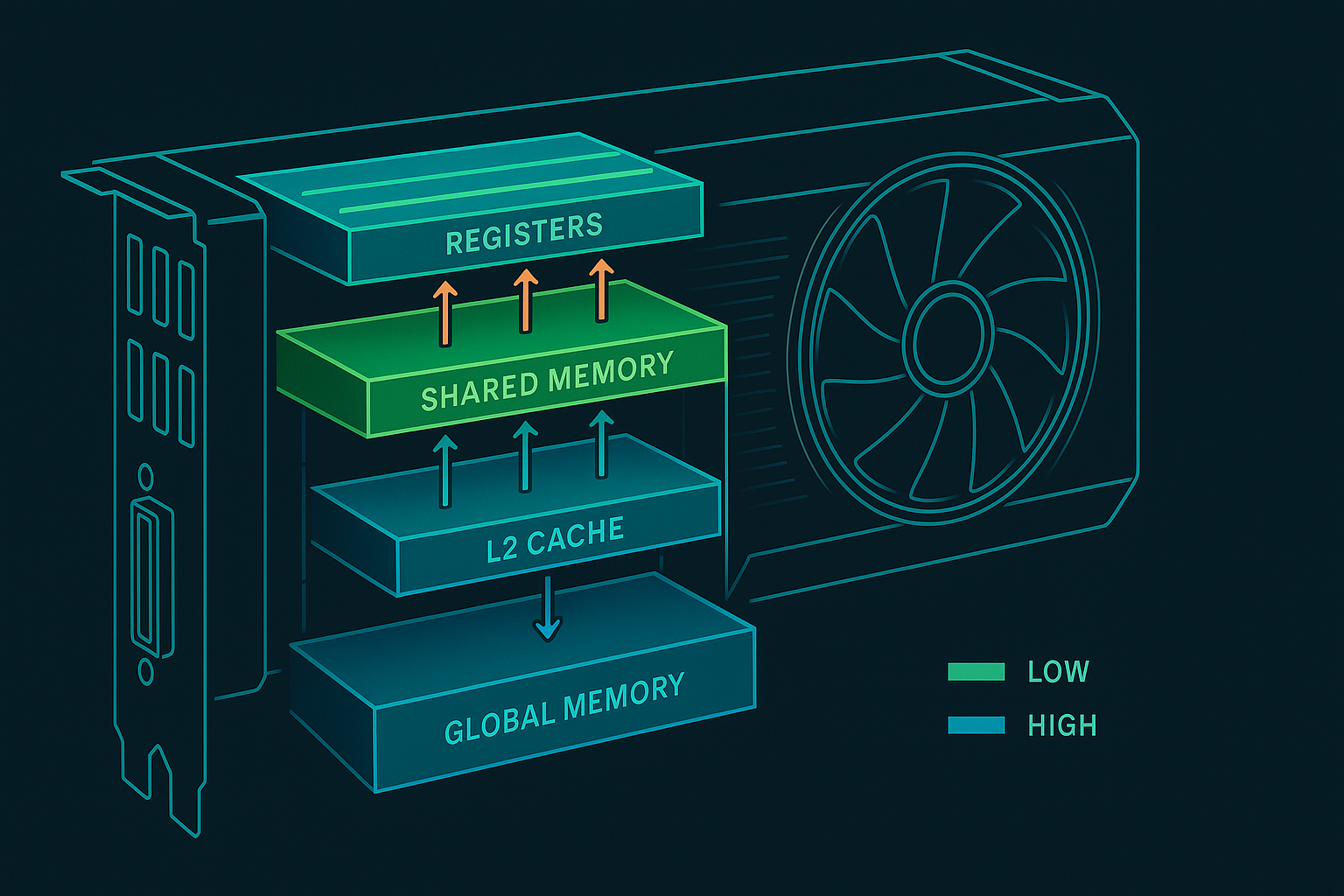
Global, shared, and register memory each have distinct latency and bandwidth. Performance comes from the right access pattern.
CUDA performance hinges on moving data efficiently through a hierarchy of memories that differ by latency, bandwidth, scope (visibility), and capacity. Raw FLOP throughput is rarely the first limiter—memory behavior, access ordering, and reuse patterns almost always dominate performance envelopes.
1. The Hierarchy at a Glance
| Level | Scope / Visibility | Approx Latency (cycles)* | Bandwidth | Capacity (per SM / device) | Notes |
|---|---|---|---|---|---|
| Registers | Thread private | ~1 | Extreme | Tens of k per SM (allocated per thread) | Allocation affects occupancy; spilling -> local memory |
| Shared Memory (SMEM) | Block (CTA) | ~20–35 | Very high | 48–228 KB configurable (arch dependent) | Banked; subject to conflicts; optional split w/ L1 |
| L1 / Texture Cache | SM | ~30–60 | High | ~128–256 KB (unified) | Serves global loads; spatial locality & coalescing still matter |
| L2 Cache | Device-wide | ~200–300 | High | Multi-MB | Coherent across SMs; crucial for global data reuse |
| Global DRAM | Device-wide | ~400–800 | High (GB/s) | Many GB | Long latency—hide with parallelism & coalescing |
| Constant Cache | Device-wide (read-only) | ~ L1 hit if cached | High (broadcast) | 64 KB | Broadcast to warp if all threads read same address |
| Texture / Read-Only Cache | Device-wide (cached) | Similar to L1 | High | N/A | Provides specialized spatial filtering & relaxed coalescing |
| Local Memory | Thread (spill/backing) | DRAM latency | DRAM | Per-thread virtual | “Local” is misnomer if spilled—same as global latency |
Indicative ranges; varies by architecture generation (e.g., Turing, Ampere, Hopper). Absolute numbers less important than ratio gaps.
Key Principles
- Reuse closest to compute: Promote frequently reused data upward (registers > shared > L1 > L2 > DRAM).
- Minimize divergence in memory patterns: Divergent addresses within a warp break coalescing and add transactions.
- Overlap where possible: Use asynchronous copies & double buffering to hide DRAM latency behind computation.
- Balance occupancy vs. registers/shared memory usage: More threads help hide latency until diminishing returns; sometimes fewer threads with better cache/block reuse win.
2. Global Memory Access & Coalescing
Warps issue memory instructions collectively. A coalesced load/store ideally maps contiguous 32/64/128-byte segments to the DRAM interface with minimal memory transactions. Poor alignment or strided patterns cause partial transactions and wasted bandwidth.
Alignment & Layout
Assume a structure:
struct Bad { float x; int flag; float y; };
Interleaving types can force awkward alignment. A SoA (structure-of-arrays) layout improves contiguous float loads:
struct Good { float* __restrict__ x; float* __restrict__ y; int* __restrict__ flag; };
Hybrid: keep hot fields together if always accessed together; otherwise separate.
Stride Pitfall
If thread t accesses A[base + t * stride] with stride > 1, each warp touches scattered cache lines. Remediation:
- Tile & transpose into shared memory.
- Use vectorized loads (
float4) when alignment permits. - Reorder loops so
titerates over the innermost contiguous dimension.
3. Shared Memory (SMEM) Deep Dive
Shared memory provides a manually managed, programmer-controlled cache. Wins arise from temporal reuse and avoiding redundant DRAM fetches.
Bank Conflicts
SMEM is organized into banks (commonly 32). Concurrent accesses by a warp to different addresses in the same bank serialize (except broadcast cases). To avoid conflicts:
- Pad leading dimension: e.g., declare
float tile[BLOCK_Y][BLOCK_X+1];. - Use swizzled indexing (XOR transpose patterns) for complex transforms.
- For matrix multiply tiles (MxK * KxN), pad K dimension if K%32==0 and access pattern causes bank modulo collisions.
Double Buffering
Load tile (stage k), compute on tile (stage k-1). Pattern:
- Asynchronous copy next tile to SMEM (cp.async on newer architectures).
__syncthreads()only when needed (barrier cost ~80–100 cycles but hidden if overlapped).- Pipeline ensures arithmetic never waits on DRAM after warmup.
Example: 2D Convolution Tile Skeleton
template<int BLOCK, int K>
__global__ void conv2d(const float* __restrict__ in,
const float* __restrict__ kernel,
float* __restrict__ out,
int W, int H) {
__shared__ float tile[BLOCK + K - 1][BLOCK + K - 1];
int tx = threadIdx.x, ty = threadIdx.y;
int ox = blockIdx.x * BLOCK + tx;
int oy = blockIdx.y * BLOCK + ty;
// Load with halo (guard): coalesced rows
for (int dy = ty; dy < BLOCK + K - 1; dy += blockDim.y) {
int iy = blockIdx.y * BLOCK + dy;
for (int dx = tx; dx < BLOCK + K - 1; dx += blockDim.x) {
int ix = blockIdx.x * BLOCK + dx;
tile[dy][dx] = (ix < W && iy < H) ? in[iy * W + ix] : 0.f;
}
}
__syncthreads();
if (ox < W && oy < H) {
float acc = 0.f;
#pragma unroll
for (int ky = 0; ky < K; ++ky)
#pragma unroll
for (int kx = 0; kx < K; ++kx)
acc += tile[ty + ky][tx + kx] * kernel[ky * K + kx];
out[oy * W + ox] = acc;
}
}
Optimizations left: vectorized loads (float4), using cp.async to stage tiles, and fusing activation functions.
4. Registers, Spilling & Occupancy
Each thread receives a register allocation at compile time. If requested registers exceed hardware limit per SM (divided among active warps), compiler spills to local memory—which lives in DRAM with L1/L2 caching. Spills turn a compute-bound loop into a bandwidth-bound workload.
Trade-Off Model
Let:
- R_per_thread = allocated registers.
- R_total_per_SM = physical registers/SM.
- Threadsper_block _Blocks_per_SM R_per_thread ≤ R_total_per_SM.
Raising R_per_thread can improve ILP (fewer re-computations, unrolled loops) but can reduce concurrent warps (occupancy). Empirical approach:
- Compile with different
-maxrregcountvalues. - Profile achieved occupancy vs. executed instructions per cycle (IPC).
- Pick point where further occupancy doesn’t reduce stall reasons: memory dependency / execution dependency.
5. L1, L2, and Cache Behavior
Modern GPUs unify user-configurable shared memory & L1 capacity. Choosing a larger SMEM carve-out may shrink L1, affecting global load hit rate. Balance:
- If your kernel has high explicit tile reuse, favor larger SMEM.
- If access pattern exhibits streaming with little temporal reuse but regular spatial locality, allow a larger L1.
L2 acts as a global victim cache: multi-kernel pipelines can benefit from reusing results if intermediate data fits. Consider kernel fusion to keep data in registers/SMEM instead of writing & rereading through L2/DRAM.
6. Read-Only, Constant & Texture Paths
Marking pointers with const __restrict__ enables read-only cache usage (on older arch via ld.global.nc / ldg). Constant memory excels when a warp broadcasts the same value; random indices kill benefit. Texture caches add hardware filtering & address normalization for 2D spatial access, often improving locality for irregular stencils.
7. Asynchronous Data Movement & Latency Hiding
Architectures >= Ampere allow cp.async to stream data from global to shared memory into stages without stalling the warp. Pattern:
- Issue N async copies (filling a stage buffer).
- Commit & wait groups while computing on prior stage.
- Overlap memory fetch for tile k+1 with arithmetic on tile k.
Add double or triple buffering to cover memory latency plus potential L2 queuing. Nsight Systems timeline helps verify overlap (look for interleaved memcpy/compute ranges).
8. Roofline Perspective
Compute performance is bounded by either peak FLOP/s or memory bandwidth times operational intensity (OI = FLOPs / bytes). For a kernel:
- Count FLOPs (static or via instruction profiling).
- Measure bytes transferred (global loads/stores * transaction width, plus replays).
- OI = FLOPs / bytes. If OI < (Peak FLOP/s / Peak Bandwidth), you are bandwidth-bound; optimize memory first.
Raising OI strategies:
- Increase arithmetic reuse per fetched byte (blocking, fused operations).
- Convert data types (FP32 → FP16/BF16) when precision permits to double effective bandwidth.
- Use tensor cores (matrix-multiply-accumulate instructions) for dense GEMM-like subproblems.
9. Warp Specialization & Cooperative Groups
Some kernels benefit from dedicating a subset of warps in a block to “producer” roles (prefetch, reduction) while others “consume” (compute). Cooperative groups + warp-level primitives (__shfl_sync) enable low-latency intra-warp reductions, bypassing shared memory and reducing bank pressure.
Example: Warp Reduction
__inline__ __device__ float warp_sum(float v) {
for (int offset = 16; offset > 0; offset >>= 1)
v += __shfl_down_sync(0xffffffff, v, offset);
return v;
}
Use after each thread accumulates partial sums; only lane 0 writes to shared/global memory.
10. Common Performance Pathologies
| Symptom | Likely Cause | Diagnostic | Remedy |
|---|---|---|---|
| High DRAM transactions, low FLOP util | Uncoalesced loads | Memory statistics (Nsight Compute) | Reorder data, vector loads, tiling |
| Many shared memory bank conflicts | Stride hitting same bank | SMEM bank conflict metric | Pad leading dimension |
| Low occupancy, many stall_memory_dependency | Register pressure or long DRAM latency | Achieved occupancy, stall reason breakdown | Reduce registers, add latency hiding ops |
| High local memory loads | Register spilling | SASS / metric for local loads | Reduce inlining, unroll selectively, use -maxrregcount |
| Cache thrash | Working set > L1, poor locality | L1/TEX hit rate | Increase tile size, restructure loops |
11. Benchmarking Methodology
- Warm-up runs (clock/power stable, JIT done).
- Collect multiple samples (variance <2%).
- Reset GPU clocks (or lock with persistence mode) for reproducibility.
- Use events (
cudaEventRecord) for kernel timing; wall clock for end-to-end. - Record environment (driver version, GPU model, clock rates) in results.
Track: achieved occupancy, DRAM throughput (GB/s), L2 hit rate, SM efficiency (% cycles issuing instructions), active warps per cycle, branch efficiency.
12. Putting It Together: Mini Case Study
Goal: accelerate 2D stencil (7-point) on a modern GPU.
Baseline kernel: direct global loads, each output reads 7 elements ⇒ OI low. Profiling shows:
- DRAM throughput at 55% of theoretical.
- L2 hit rate 45% (poor reuse).
- Achieved occupancy 100% but stall_memory_dependency dominates.
Optimizations:
- Shared memory tile + halo: reduces redundant DRAM loads (~7→1.2 average loads per output). DRAM throughput drops (less data moved) while compute occupancy same; memory dependency stalls fall.
- Double buffering + cp.async: Overlaps global fetch for next tile; kernel time -18%.
- Register blocking: Each thread computes 2×2 outputs; adds ILP, moderate register increase but still acceptable occupancy; -12% time.
- Precision reduction (FP32→FP16 accumulate FP32): If error tolerable, halves bytes; bandwidth headroom yields another -20% time.
Result: 2.3× speedup overall, moving kernel closer to compute-bound; roofline placement shifts right (higher OI) then up (higher utilization).
13. Checklist Before Shipping
- Are all major global memory streams coalesced? (Check sector requests vs. transactions.)
- Are shared memory bank conflicts negligible (< a few % of instructions)?
- Any local memory (spill) loads left? If yes, justify.
- Achieved occupancy above “latency hiding threshold” (often ~30–40% for mature kernels)?
- Roofline: bound by memory or compute? Further work aligned accordingly.
- Kernel launch params (block size, grid size) chosen via sweep—not guesswork.
- Regression tests cover numerical correctness after precision or reordering changes.
14. Further Reading (Titles)
- “Optimizing Parallel Reduction in CUDA” (classic reduction patterns)
- “Efficient Shared Memory Usage in Stencil Computations”
- “GPU Roofline Model: Application Characterization”
- “Asynchronous Copy (cp.async) Best Practices”
- Vendor architecture whitepapers (memory subsystem sections)
- Nsight Compute / Systems User Guides
15. Summary
GPU performance is primarily a data movement orchestration problem. Exploit registers for immediacy, shared memory for cooperative reuse, caches for spatial locality, and asynchronous pipelines for overlap. Optimize operational intensity and latency hiding mechanisms before micro-tweaking instruction sequences. A disciplined measurement loop (profile → hypothesize → transform → re-profile) turns the memory hierarchy from an obstacle into an enabler of near-peak throughput.